Stanford CS106L 笔记——上半部分
笔记内容来自于Stanford CS106L的2019年秋季视频,[链接](CS 106L Fall 2020 - Guest Lecture: Template Metaprogramming - YouTube)。
因为这门课的内容实在太庞杂了,只看一遍视频的话,很多东西记不住。如果后续想回顾的话,再去找对应内容又太花时间,索性边看边记了。上半部分主要是C++中STL相关的一些概念,学习泛型编程的思想。
Lecture 1: Streams I
C++ 的流库(Streams Library),是一个函数集合,允许你从各种来源读取和写入格式化数据。流库允许你的程序向用户打印文本并回读响应。它还允许你从外部文件加载持久数据并将自定义信息保存在磁盘上。
<<和>>运算符
<<称为流插入运算符(stream insertion operator),其是一个 C++ 运算符,用于将数据推送到流对象中。代码例子:
1 |
|
>>成为流提取运算符(stream extraction operator)。在语法上,流提取运算符时流插入运算的镜像。代码例子:
1 | int myInteger; |
注意:使用 cin 时,不应像使用 cout 那样读入 endl。
fstream
C++ 提供了一个名为<fstream>(文件流)的头文件,它导出 ifstream 和 ofstream 类型,即执行文件 I/O 的流。 ifstream 代表输入文件流(不是“可能是流的东西”),而 ofstream 代表输出文件流。而使用fstream可以同时代表输入和输出文件流。
要创建从文件读取的 ifstream,语法如下:
1 | ifstream myStream("myFile.txt"); |
也可以这么做:
1 | ifstream myStream; // Note: did not specify the file |
但推荐按前一种来,因为符合RAII的思想。
当我们尝试从与打开文件无关的 ifstream 中读取数据时,读取将失败并且您将无法取回有意义的数据。尝试打开文件后,你应该使用.is_open()成员函数检查流是否有效。例如,以下代码用于打开文件并在出现问题时向用户报告错误:
1 | ifstream input("myfile.txt"); |
ifstream 的输出对应物是 ofstream。与 ifstream 一样,可以通过使用 .open() 成员函数或通过在创建 ofstream 时指定文件来指定要写入的文件,如下所示:
1 | ofstream myStream("myFile.txt"); // Write to myFile.txt |
注意:如果你尝试使用 ofstream 写入不存在的文件,ofstream 将为你创建文件。但是,如果您打开一个已经存在的文件,ofstream 将覆盖该文件的所有内容。小心不要在没有先备份的情况下写入重要文件!
流库是 C++ 中较旧的库之一,ifstream 和 ofstream 类上的open函数早于字符串类型。如果你有一个存储在 C++ 字符串中的文件名,你需要将字符串转换为 C 风格的字符串,然后再将其作为参数传递以打开。这可以使用字符串类的 .c_str() 成员函数来完成,如下所示:
1 | ifstream input(myString.c_str()); // Open the filename stored in myString |
当文件流对象超出范围时,C++ 会自动为您关闭该文件,以便其他进程可以读取和写入该文件。如果要提前关闭文件,可以使用 .close() 成员函数。调用 close 后,读取或写入文件流将失败。
getInteger实现
流的状态
在使用流进行读写时,其会有四种状态。这四种状态指明了流是在正常工作,还是发生了某种错误。其内容如下:
- Good bit:准备好读/写。
- Fail bit:之前的操作失败,导致以后的操作失败。
- EOF bit:到达缓冲区内容的末尾,导致以后的操作失败。
- Bad bit:外部错误,导致后续操作失败。
1 | int stringToInteger(const string& str) { |
以上代码的另一种版本:
1 | int stringToInteger(const string& str) { |
Lecture 2: Streams II
cout and cin
cout(用于字符输出)是一个连接到控制台的流,一个显示纯文本数据的文本窗口。通过 cout 推送的任何信息都会显示在控制台中,因此您可以将 cout 视为向用户显示数据的一种方式。另一个称为 cin(字符输入)的流对象,它允许您直接从用户读取值。
将>>和cin搭配使用会有以下问题:
- cin 将整行读入缓冲区,但会为您提供以空格分隔的标记
- 缓冲区中的垃圾会导致无法在正确的时间提示用户输入
- 当cin失败时,所有未来的 cin 操作也会失败
对于问题1,当我们在终端输入hello ABC时,整个字符串都将进入缓冲区,但使用>>去从中提取内容时,>>只会读取到空格为止,也就是只读取到hello,但我们想将hello ABC读取到一个变量中。此时,就会发生错误。为了避免这样的问题,我们应该使用getline,用法:
1 | string inputStr; |
此时,使用getline的getInteger代码如下:
1 | int getInteger(const strnig& prompt, const string& reprompt) { |
cin.ignore()忽略一个输入stream的字符。getline()不会忽略之前的换行符号,如果其前面有换行符,需要在其之前先使用cin.ignore()。
auto
auto 自动给定变量类型,使用它可以提供很多方便。可以在一些具体返回值不重要的地方用,但是函数返回值不要用。注意事项:
- 当从上下文的类型很清楚时,可以使用
- 当确切的类型不重要时,可以使用
- 当它明显影响可读性时,不要使用
pair
pair<type, type> 类似python的tuple,允许两个元素组成一个组合。
c++17允许结构化绑定(structured bindings), 这允许你解开一个组合中变量,例如:
1 | auto [min, max] = findPriceRange(dist); |
注意:而且也可以直接解开vector,但是需要注意变量数目跟vector内的元素数目要对应。
你还可以在结构体上使用结构化绑定,代码例子:
1 | struct PriceRange { |
注意:绑定发生的顺序与变量在结构中的放置顺序相同。
initialization
在C++中,依据类型,有非常多初始化变量的方法。为了解决这个,C++11引入了一个新方式——uniform initialization。例子:
1 | int main() { |
stringstream的使用时机
处理字符串
Simplify “/./a/b/..” to “/a”
格式化输入/输出
uppercase, hex, and other stream manipulators
解析不同类型
stringTolnteger() from previous lectures
注意:如果你只需要拼接字符串,str.append()比stringstream更快。
Lecture 3: Sequence Containers
序列容器提供序列元素的访问,其包含以下几种类别:
std::vector<T>std::deque<T>std::list<T>std::array<T>std::forward_list<T>
vector的边界检查
对于一个vector对象——vec来说,vec[index]不会检查边界,如果访问不存在的元素,程序不会出现任何提示,而vec.at(index)会检查边界,并对错误访问进行提示。这里vec[index]不出现任何提示,是当访问地址不在保护区中时,而当访问地址在保护区时,会出现segmentation fault,并终止程序。
那为什么std: : vector不进行默认的边界检查?因为C++的设计哲学是支持你想做的任何事情,认为你所写的代码都非常正确,并且程序运行速度要快。而如果默认进行边界检查,这样会降低正确程序的运行速度。
We saw this! In practice, vec[i] on an out-of-bounds index fails silently on Windows, and continues as though nothing happened on Mac!
Stanford CS106L 2019 Lecture 4
vector与deque
vector仅支持在最后添加元素,没有默认的push_front,如果在最前方添加元素,速度会很慢,而deque支持两边添加。
那既然deque比vector多了运行更快的push_front,为什么还要使用vector?因为,vector的push_back和元素访问要比deque更快。
选择使用哪一个数据类型?
“vector is the type of sequence that should be used by default… deque is the data structure of choice when most insertions and deletions take place at the beginning or at the end of the sequence.”
–C++ ISO Standard (section 23.1.1.2):
Lecture 4: Associative Containers & Iterators
Container Adaptors
Stack:只需将向量/双端队列的功能限制为只允许push_back和pop_back。
Queue:只需将双端队列的功能限制为只允许push_back和pop_front。
同时,Stack和Queue都只允许访问顶部的元素。
C++的stack和queue基于其它容器实现,它们主要起到一个适配的作用,因为被称为Container Adaptors。可自行翻阅c++参考文档的[stack](std::stack - cppreference.com)和[queue](std::queue - cppreference.com)。
Associative Containers
关联容器(Associative Containers)使用键(key)而不是索引(index)访问数据,其包含以下几种类别:
std::map<T1, T2>std::set<T>std::unordered map<T1, T2>std::unordered set<T>
不同Associative Container的本身特点:
map/set:基于键的排序属性。键需要使用 <(小于)操作符进行比较。
unordered map/set:基于哈希函数。键需要被定义是如何被哈希的。
对以上两种大的类别来说,你可以为自己的类定义 < 和散列函数运算符。
不同Associative Container的使用特点:
map/set:键按顺序排列,可以更快地遍历一系列元素。
unordered map/set:可以更快地通过键访问单个元素。
map
对于一个map来说,map.at(key)如果访问一个不存在的键会报错,而map[key]会自动插入value对应数据类型的默认值,比如,int类型对应的value将初始化为0。
经常会使用map.count(key)返回的0/1来判断对应键是否存在,而C++20引入了map.contains(),其返回true/false,更符合直觉。
set
集合只是没有值的map的特定情况。或者,你可以将map的值视为真(如果存在)或假,这样,map就变成了set。
从字面上看,set与C++中map的所有功能相同,但不包括元素访问。
Iterator
迭代器(Iterator)允许对任何容器进行迭代,无论容器是否有序。
迭代器可以让我们以线性方式查看非线性集合。这其实就是将非线性的、具体的查看方式给封装了,我们在使用时无需关注其细节。
迭代器如何能够以“顺序”的方式表示非线性集合?实际上,它们在二叉树上进行有序遍历。
几乎所有 C++ 容器都有迭代器。为什么迭代器这么强大?
- 许多场景都需要查看元素,而不管存储这些元素的是什么类型的容器。
- 迭代器可以让我们以标准化的方式遍历元素序列。
- C++ 是巨大的!
Lecture 5: Advanced Containers
Multimap
map存储唯一的键,但有时我们想让map有相同的键,但它们指向不同的值,这就引入了multimap。multimap没有[]操作符,通过在键值std::pair上调用.insert来添加元素。例子:
1 | multimap<int, int> myMMap; |
Map Iterators
map的迭代器略有不同,因为我们既有键又有值。map<string, int>的迭代器指向 std::pair<string, int>。
std::pair Class
pair是捆绑在一起的两个对象。例子:
1 | std::pair<string, int> p; |
生成pair的更快方式:
1 | std::pair<string, int> p{"Phone number", 65072323001}; |
map iterators例子:
1 | map<int, int> m; |
find vs. count
myMap.count (key)1
2if (myMap.count (key) == 0)
cout << "Not Found";std::find (myMap.begin(), myMap.end(), key)1
2if (find(myMap.begin(), myMap.end() , key) == myMap.end ())
cout << "Not Found":
count实际上只是对find函数的调用!所以find稍微快一点。
Iterator Types
总共有5种不同类型的迭代器,分别为:
- Input
- Output
- Forward
- Bidirectional
- Random access
所有的迭代器都有以下共性:
- 可以从现有的迭代器创建
- 可以使用++进行增加
- 可以通过==和! =进行比较
Input Iterators
用于顺序、单通道输入(single-pass input)。只读,即只能在表达式的右侧取消引用。
1 | vector<int> v = ... |
用例:
find和count- input streams
Ouput Iterators
用于顺序、单通道输出(single-pass output)。只读,即只能在表达式的左侧取消引用。
1 | vector<int> v = ... |
用例:
copy- output streams
Forward Iterators
除了组合输入和输出迭代器功能之外,可以进行多次输出。可以读取和写入(如果其不是const迭代器)。
1 | vector<int> v = ... |
用例:
replacestd forward_list(sequence container, think of as singly-linked list)
Bidirectional Iterators
除了与前向迭代器相同之外,可以向后使用。可以使用减量运算符--。
1 | vector<int> v = ... |
用例:
reversestd::map和std::setstd::list(sequence container, think of as doubly-linked list)
Random Access Iterators
除了与双向迭代器相同之外,还可以使用+和- 操作符进行任意数量的递增或递减。
1 | vector<int> v = ... |
用例:
std::vector,std::deque,std::string- Pointers
Lecture 6: Templates I
template functions
通过使用template,可以让同一段函数代码支持不同的数据类型。
1 | template <typename T> |
Generic Programming and Lifting
查看以下示例代码对参数的假设,并质疑它们是否真的有必要。我们是否可以通过放松约束来解决更普遍的问题?
代码1,How many times does the integer [val] appear in a vector of integers?
1 | template<> |
代码1是最为常见的,面向特定数据的代码,如果没有泛型编程的思想,为了解决这个问题,我肯定就直接写成这样的函数了。但很明显,vector中并不总是存储整型数字,因此我们将查找的数据类型抽象为模版类型,得到代码2。
代码2,How many times does the [type] [val] appear in a vector of [type]?
1 | template<typename DataType> |
我们并不总是想在vector中计算元素的出现次数,也可能是map,set等其他抽象数据类型。因此,我们将存储元素的对象进行抽象,得到代码3.
代码3,How many times does the [type] [val] appear in a [collection] of [type]?
1 | template<typename Collection, typename DataType> |
但代码3实际上并不能工作,因为并非所有的抽象数据类型都能通过index进行访问,比如map和set就不能。所以,我们引入迭代器,得到了代码4。
代码4,How many times does the [type] [val] appear in a [collection] of [type]?
1 | template<typename Collection, typename DataType> |
代码4可以说将代码进行了很大程度的抽象,但实际上这段代码还有最后一个假设。代码4总是会从抽象数据类型的头部遍历到尾部,但有时我们只想遍历抽象数据类型的一部分。所以,我们将控制起点和终点的控制权交出,得到代码5。
代码5,How many times does the [type] [val] appear in [a range of elements]?
1 | template<typename InputIterator, typename DataType> |
代码5是最终版本,这其实也就是C++一些函数的书写方式。比如,我们想要使用sort()对抽象数据类型vec的一部分进行排序,代码即可写为sort(vec.begin(), vec.begin()+4)。
Lecture 7: Templates II and Functions
如果通过以下方式调用上节课的代码5,将会出现错误。
1 | vector<int> v1{1, 2, 3, 1, 2, 3}; |
出错原因:编译器将从字面上用你实例化它的任何内容来替换每个模板参数。下面代码第一行的模版代码将直接失效,同时参数val的数据类型将变为vector<int>::input_iterator。同时,因为*iter的类型为int,其不能与迭代器进行比较,因而报错。
1 | // template<typename InputIterator, typename DataType> |
这意味着,模板函数实际上定义了每个模板参数必须满足的隐式接口,传入的模版参数必须支持函数所假设其具有的操作。就是说,代码中对模版参数进行的种种操作,模版参数必须支持,不然,编译器就会出现很复杂的报错。以代码5为例,两个模版参数需要分别支持以下操作:
InputIterator must support
- copy assignment (iter = begin)
- prefix operator (++iter)
- comparable to end (begin != end)
- dereference operator (*iter)
DataType must support
- comparable to iter
C++20概念:named requirements on the template arguments
1 | template<typename It, typename Type> |
第1-2行的代码显式声明了模版参数所需要满足的性质。Input_Iterator<It> 指明It需要是input iterator。没听清楚Iterator_of<It>具体指代什么,在参考网站也没找到。Equality_comparable<Value_type<It>, Type>指明It经过取消引用之后,其数据类型必须跟Type相同。这样的话,编译错误提示就会通过第1-2行抛出,而不是通过下面的具体操作代码抛出。
参考链接:Named Requirements - cppreference.com
functions and lambdas
再看之前的代码5,对其进行提炼。在这里其原问题为:How many times does the [type] [val] appear in [a range of elements]?更进一步,代码5解决的问题可以描述为:How many times does the element satisfy “equal [val]” in [a range of elements]?
1 | template<typename InputIterator, typename DataType> |
这里引入一个概念:谓词(predicate)是一个函数,它接受一些参数并返回一个布尔值。
那么,代码5解决的问题其实就是:代码5解决的问题可以描述为,How many times does the element satisfy “[predicate]” in [a range of elements]?最后,得到代码6如下。
1 | template<typename InputIterator, typename DataType> |
此后,我们可以用predicate调用代码6的函数。示例:
1 | bool isLessThan5(int val) { |
实际上,predicate也可以写为模版的形式。示例:
1 | template <typename DataType> |
写具有相似目的的小代码很烦人,我们可以自然地想到添加一个额外参数。但这不起作用,因为该函数必须是一元谓词(unary predicate),这将导致编译错误。
1 | template <typename DataType> |
Pre-C++11 solution: function objects(“functors”)
Key Idea: 创建一个可以像函数一样工作的对象,因为它有一个( )运算符 。
1 | class GreaterThan { |
C++11 solution: lambda functions
1 | int main() { |
lambda
lambda的语法解析:
1 | auto func = [capture-clause](parameters) -> return-value { |
lambda的capture同样可以使用引用。例子:
1 | set<string> teas{"black", "green", "oolong"}; |
并不建议的使用方式:
1 | // capture all by value, except teas is by reference |
Lecture 8: Functions and Algorithms
前半部分关于函数的好像都跟之前的重复了,没啥新内容可记的。
一些常用的std算法
std:stable_partition
作用:稳定排序,将原来的范围划分成两部分。重新将[first,last)中的元素排序,所有符合一元谓词条件的返回true,不符合的返回false。和std::partition不同的是,stable_partition是稳定的,保持原有元素的相对顺序。
示例:
1 | std:string deparment = "CS"; |
std:copy_if
作用:用于复制容器的元素,它将容器给定区间中满足对应条件的元素,从开始位置复制到另一个容器中(也是从开始位置逐个放置)。
示例:
1 | string dep = "CS"; |
但是,以上代码不能运行。因为要复制到的目标vector--csCourses在刚开始的容量是固定的,而std::copy_if又不是vector--csCourses的成员函数,所以当要插入的元素数量超过默认数量时,vector--csCourses并不会自动扩充容量,会导致错误。这就需要使用back_inserter,来使得对应数据结构能够在需要时,扩充数据空间。back_inserter实际上是iterator adapter,它接受一类容器,并返回一个可以将数据插入对应容器的特殊iterator。此类iterator可以动态扩充对应容器的存储空间。
1 | string dep = "CS"; |
std:copy
作用:将容器给定区间中的元素复制到另一个容器中。
示例:
1 | std::copy(csCourses.begin(), csCourses.end(), std::ostream_iterator<Course>(std::cout, "\n")); |
std:remove & std:remove_if
作用:用于移除元素,std:remove_if只是多加了一个判断条件。
注意:std::remove并不能改变对应容器的大小,因为他并不能访问对应容器的成员函数。
技巧:
1 | // 用于删除移除元素之后的无用空间 |
以上都只简略记一下,知道是干什么的,具体的详细用法还是要翻参考手册。
Lecture 9: STL Summary
STL’s Abstraction
抽象使我们能够表达问题的一般结构,而不是其实现的细节。与其解决具体实例,不如在一般环境中解决问题。出于这种考虑,就有了STL(Standard Template Library)的提出。STL大致可分为五个模块的内容,它们之间的关系如下图所示。
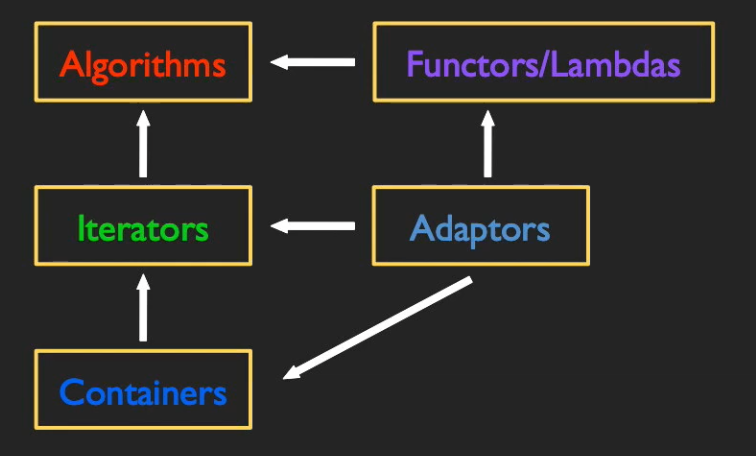
STL本质是对问题的一系列抽象描述,下面将简要描述这一抽象过程。
在最开始的C++学习中,我们会学习到很多的基本(basic)类型,比如char,int等。从概念上来说,每个类型都是一个单一值(single value)。那么,我们很自然地会想:我们可以跟踪基本类型的集合,而不管类型是什么?(Can we keep track of a collection of basic types, regardless of what the type is?)
对上一问题的回答是:容器(Container)。容器让我们可以对基本类型执行操作,而不管基本类型是什么。在使用容器时,只需要预先表明所需要存储的数据类型即可,与此同时,无论容器中是什么基本类型,容器的操作都是固定的。
既然现在有了很多不同的容器,那么我们能否对任意容器进行一致的操作?(Can we perform operations on containers regardless of what the container is?)
对上一问题的回答是:迭代器(Iterator)。迭代器允许我们从正在使用的容器中抽象出来,这类似于容器允许我们从所使用的基本类型中抽象出来。有了迭代器,我们可以编写诸如排序、搜索、过滤、分区等各种操作,以用于几乎任何容器。
更进一步,无论迭代器用于什么类型的容器,我们都可以对迭代器进行操作吗?
对此,STL的回答是:算法(Algotithm)。算法对迭代器进行操作,这使它们可以在多种类型的容器上工作。并且,算法经常应用仿函数(Functor),以泛化算法的应用。
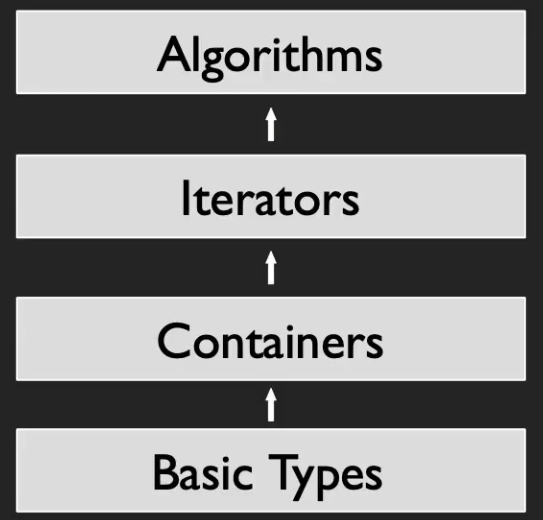
至此,我们可以得到STL的整个抽象层次如上图所示。最后,引用STL发明人的发言如下:
“As mathematicians learned to lift theorems into their most general setting, so I wanted to lift algorithms and data structures.”
- Alex Stepanov, inventor of the STL
不得不说,编程学到深处,确实是在学数学,如果你想构建出一系列工具原型的话。之前的我还不以为然,只能那时的自己只看到了表象。
STL Example
这部分主要是讲了如何利用所学知识去构建一个实际可用的算法来实现问题测量(stylometry)。
std::transform
作用:std::transform在指定的范围内应用给定的操作,并将结果存储在指定的另一个范围内。使用std::transform函数需要包含<algorithm>头文件。
一个常见的用法是进行大小写转换,例子:
1 | string fileToString(ifstream& file) { |