Stanford CS106L 笔记——下半部分
笔记内容来自于Stanford CS106L的2019年秋季视频,视频链接。
下半部分主要是C++的类相关概念以及C++11之后的一些新特性,学习如何进行现代的C++编程。
Lecture 10: Classes and Constant
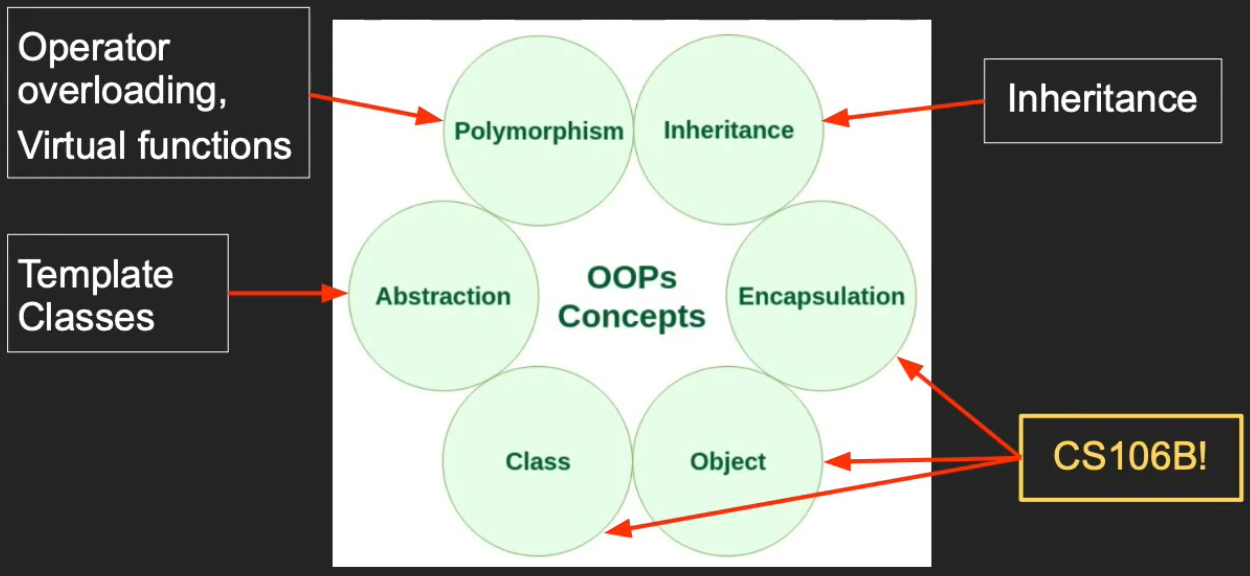
面向对象概览
在CS106B已经学过了简单的类、对象和封装,后续将对抽象,继承和多态进行更进一步的学习。C++整体的面向对象内容如下图所示,我可以根据这张图初步理清整个体系的各个主要模块。
为什么C/C++文件后缀有这么多的拓展?
- 头文件:.h、.hh、.hpp
- 源文件:.cc、.cpp、.cxx、.c++、.C
这取决于编译器!参考
- 从历史上看,使用 .C(即大写 C)
- 现在Unix多使用.cc,Unix以外多使用.cpp
- .h 在技术上适用于C程序,因此如果混合C和 C++ 代码,请使用.hh 代替
const-变量
为什么不使用全局变量?
- “全局变量可以被程序的任何部分读取或修改,因此很难记住或推理每一种可能的用途”
- “全局变量可以由程序的任何部分获取或设置,任何有关其使用的规则都可以很容易地被破坏或遗忘”
使用const的好处
示例:
1 | void f(int x, int y) { |
在以上代码中,f函数只是为了对x和y进行一些比较,我们显然不会在该函数中对待比较变量进行修改。但有时,我们会由于疏忽导致一些代码出现错误,而自己又很难找到bug。在上面代码的第4行最右边,我们本期望写成y==-1,但却写成了y=-1,这就导致了预期之外的错误。而如果在函数参数处使用const,编译器就可以为我们找到bug,因为const使得该函数不能修改对应参数。使用const的代码如下:
1 | void f(const int x, const int y) { |
以上代码是一个相当基本的用例,但这真的是const的所有好处吗?并不是,下面通过例子学习。
因使用const而出错的例子
假设我们想对一个星球的人数进行统计,写出代码如下:
1 | long int countPeople(Planet& p) { |
当调用countPeople时,其内部又调用了另外三个函数,这些函数会对countPeople所接受的参数p进行修改,但我们并不想修改p,所以我们会想到使用const。代码如下:
1 | long int countPeople(const Planet& p) { |
但以上代码会产生编译错误,因为addLittleHat等其他函数并没有对传入参数进行const的限制。在 p 上调用addLittleHat就像设置一个非const变量等于一个const变量,编译器不允许这么做。如果要解决这个问题,这可能就需要使得addLittleHat函数也用const修饰参数p,但这么又使addLittleHat无法在函数体中对p做出修改。这使得我们陷入了两难的境地。这时可能就需要使用mutable来解除这一限制,但mutable的使用也需要再权衡一番,因为随意使用mutable的话,等于const的使用也没有意义了。
总结起来,const允许我们推断变量是否会改变。代码描述如下:
1 | void f(int& x) { |
const-指针
使用带有const的指针有点棘手,如有疑问,请从右到左阅读。
1 | // constant pointer to a non-constant int |
const-迭代器
- 请记住,迭代器的作用类似于指针
const vector<int>::iterator itr的行为类似于int* const itr- 要使迭代器只读,请定义一个新的
const迭代器
例子1:
1 | vector v{1, 2312}; |
例子2:
1 | const vector<int>::iterator itr = v.begin(); |
const回顾
一些小的注意点:
- 在大多数情况下,任何没有被修改的东西都应该被标记为
const - 通过
const引用传递优于传递值- 对原语(bool、int等)来说,并不正确(因为本身就是一个很小的值,传值与传引用并没有很大的开销区别)
- 成员函数应该同时具有
const和非const迭代器 - 从右到左阅读,以了解指针
- 请不要制造炸毁地球的方法
const对象:
通过只允许调用const函数并将所有公共成员视为const来保证对象不会改变。这有助于程序员编写安全的代码,并为编译器提供更多信息以用于优化。
const函数:
保证该函数不会调用除const函数之外的任何东西,并且不会修改任何非静态(non-static)、非可变(non-mutable)成员。
根据所学知识,解释以下代码中每个const的含义:
1 | const int* const maClassMethod(const int* const & param) const; |
第1个:函数返回的指针指向一个const int值
第2个:函数返回一个const指针
第3个:param指针指向一个const int值
第4个:该函数接受一个const指针param
第5个:这是一个const成员函数,即这个函数不能修改这个(this)实例的任何变量
什么时候使用这些不同用法?参考链接:const before parameter vs const after function name c++ - Stack Overflow
Lecture 11: Operators
主要通过一系列代码去讲运算符重载。
重载的一般经验法则
- 由于C++的语义,某些运算符必须实现为对应类的成员函数(例如[]、()、->、=)。
- 有的必须以非成员函数的方式执行(例如,<<,如果您正在为rhs而不是Ihs编写类)。(自己理解:lhs左参数,rhs右参数)
- 如果是一元运算符(例如 ++),则将其作为成员函数实现。
- 如果是二元的且同等对待两个操作数的运算符(例如,两个都未更改),将其实现为非成员函数(可能是友元函数)。示例:+、<。
- 如果是二元的且不是同等对待两者的运算符(更改了Ihs),则实现为成员函数(允许轻松访问 Ihs 的私有成员)。示例:+=。
为什么要通过非成员的方式重载<<?
假设我们可以通过成员的方式去重载,这样相当于我们对ostream添加了一个成员函数。但ostream是STL库的内容,一般来说,其只可使用,而无法更改。所以,我们无法通过成员的方式去重载<<,转而通过非成员的方式重载。
示例代码:
1 | ostream& operator<<(std::ostream& os, const Fraction& f) { |
但不是Fraction成员函数的<<如何访问其私有变量呢?使用friend关键字,将对应函数声明为友元函数。
1 | class Fraction { |
一些关键要点
- 始终考虑是否要使用const修饰参数。在这里,我们正在修改流,而不是Fraction结构,所以,要用const修饰Fraction。
- 返回引用,以支持链式 << 的调用。
- 这里我们重载了<<,所以我们的类作为rhs工作,但是我们不能改变Ihs(stream library)的类。
- 当你需要实现一个非成员函数,却又需要访问私有变量时,使用
friend。
Principle of Least Astonishment(POLA)
以上标题的字面翻译:最小惊奇原则。基本意思,当你正在使用实现他人需要使用的代码时,你最好通过别人不会感到惊讶的方式去实现它。
“If a necessary feature has a high astonishment factor, it may be necessary to redesign the feature”.
设计运算符主要是为了模仿传统用法(Design operators primarily to mimic conventional usage)
对对称运算符(+,-等)使用非成员函数实现(Use nonmember functions for symmetric operators)
以代码举例:
1
2
3
4
5
6Fraction a {3, 8};
Fraction b {11, 8};
// equivalent to a.operator+(0.5), compiles
if (a + 1 == b) cout << "I <3 fractions!";
// equivalent to 0.5.operator+(a), does not compile
if (1 + a == b) cout << "I <3 fractions!";如果以成员函数实现+,那么只有一行判断代码可行,而第二行不可行,因为我们只给Fraction这一类实现了对应的运算符。但第二行判断代码是很常见的使用方式,我们需要支持这样的使用,所以需要通过非成员函数实现+。
始终提供一组相关运算符中的所有运算符(Always provide all out of a set of related operators)
举例来说,如果你实现了==运算符,那你需要把!=,<等一系列逻辑比较运算符也实现了。因为如果没有实现,当用户使用其他运算符,却发现没有时,会感到惊讶。
Lecture 12: Special Member Functions
特殊成员函数的初步理解:如果你没有在你的类中进行声明,那么编译器将会为你创建对应的成员函数。
构造函数
使用初始化列表的好处:当传入参数和成员变量同名时,可以避免使用this指针。
1 | // 因为传入参数和成员变量同名,我们需要使用this指针进行区分 |
copy operations
特殊成员函数(通常)由编译器自动生成,其类别如下:
- 默认构造(Default constructor):创建没有参数的对象。
- 拷贝构造函数(Copy constructor):对象被创建为现有对象的副本。
- 拷贝赋值(Copy assignment):现有对象被替换为另一个现有对象的副本。
- 析构函数(Destructor):对象在超出其作用域时被销毁。
在以下代码中,判断每一行所对应的StringVector对象所调用的特殊成员函数。
1 | Stringvector function(Stringvector vec0) { // 拷贝构造函数。因为参数是传值的,所以会创建一个原对象的拷贝 |
拷贝操作必须执行的任务
拷贝构造函数:
使用初始化列表拷贝赋值正确的成员(int、其他对象等)
Use initializer list to copy members where assignment does the correct thing.(int, other objects, etc.)
当赋值不起作用时,深拷贝所有的成员(指向堆内存的指针)
Deep copy all members where assignment does not work.()pointers to heap memory)
拷贝赋值:
清理现有对象中即将被覆盖的所有资源
Clean up any resources in the existing object about to be overwritten.
当赋值起作用时,使用初始化列表拷贝成员
Copy members using initializer list when assignment works.
当赋值不起作用,深拷贝成员
Deep copy members where assignment does not work.
一个问题
默认的拷贝构造函数会将指针也赋值到一个新的对象,这意味着两个对象在本质上都是一个对象,修改其中一个,另一个内容也随之修改,并没创建我们所想要的内容相同,但地址不同的对象。所以,我们需要实现自己的拷贝构造函数。
拷贝构造函数
1 | StringVector::StringVector(const StringVector& other) noexcept : |
拷贝赋值
1 | // 应该支持以下操作: |
阻止拷贝的方法
1 | class LoggedVector { |
适用的情况:对于ifstream这种对象,我们从中读入与读出信息,并不想对其本身进行拷贝。意思是对于这类对象,只有它们的内容才是有意义的,对它们本身做拷贝并不能带来有用的信息。
何时写自己特殊成员函数
- 当编译器生成的默认函数不起作用时
最常见的原因:所有权问题
成员是类外部资源的句柄。(例如:指针、互斥量、文件流。) - 如果显式地定义(或删除)拷贝构造函数、拷贝赋值或析构函数,则应定义(或删除)所有这三个。
理由是什么? 因为定义其中之一的事实意味着你的成员之一存在需要解决的所有权问题。而所有权问题正是我们需要自定义特殊成员函数的原因之一。
注意:如果默认操作有效,则不要定义你自己的自定义操作。
copy elision和RVO(return value optimization)
拷贝省略(copy elision)和返回值优化(RVO),是C++11及之后语言标准中定义的编译优化技术。中心思想:一个函数若直接返回类对象,一般会生成临时类对象变量,这需要多次调用拷贝构造函数(copy constructor),造成效率低下。这项技术让编译器对此优化,省略其中的拷贝构造环节,达到提升效率的目的。
一个[参考链接](浅谈C++11标准中的复制省略(copy elision,也叫RVO返回值优化)_知行合一2018的博客-CSDN博客_c++11 rvo)。
Lecture 13: Move Semantics
std: :vector<T,Allocator>: :emplace_back
作用:当向vector插入元素时,可以避免额外创建对象。代码:
1 | // Referece link:https://en.cppreference.com/w/cpp/container/vector/emplace_back |
lvalues and rvalues
和右值的定义。
基本定义
- 左值(lvalues)是具有名称(身份)的表达式。
- 可以使用地址运算符(&var)查找地址
- 右值(rvalues)是没有名称(身份)的表达式。
- 临时值
- 使用地址运算符(&var)找不到地址
直观但技术上并不正确的理解:左值可以出现在赋值的两侧,但右值通常只能出现在赋值的右侧。
代码例子
以下每个表达式的值类别是什么?
1 | int val = 2; // lvalue = rvalue |
左值引用使用一个&定义与右值引用用两个&定义,示例如下:
1 | int val = 2; |
一个C++的编译错误
在写代码时,可能会碰到错误:"Invalid non-const ref of type X& from r-value of type X"。示例代码:
1 | void nocos_Lref(vector<int>& v); |
这里的主要错误就是变量的左右值绑定错误,左值和右值引用必须严格对应左值和右值,否则就会发生错误。而另外一种解决方法是将函数的左值引用参数用const修饰,以确保函数不会修改右值(因为右值无法通过地址运算符找到地址,一般不能出现在赋值的左侧)。
这里其实也回答了自己之前在CS106B学习递归时候所碰到一个问题,自己有时会将v2+v3这种右值传入递归函数,以避免声明一个变量,方便书写,但这样就会碰到以上类型的报错。自己在写的过程中,根据编译错误提示,发现用const修饰对应参数,就可以避免这个问题,但我本质并不知道为什么要这样。根据这里的学习,问题就可以得到解答。
move operations(c++11)
move semantics的基本想法:如果一个变量是临时变量,其马上就要消失,那我们可以“偷取”其资源。我们可以“偷取”右值的资源而不可以“偷取”左值的资源,因为右值本质是一个临时变量,马上就会消失,而左值是有身份的,在代码运行时会一直存在。如果我们投取了左值的资源,那原有左值对应的资源是什么呢?所以,这样的操作不被允许。
为什么右值是move semantics的关键?
- 作为左值的对象不是一次性的,因此您可以从中复制,但绝对不能从中移动。
- 作为右值的对象是一次性的,因此您可以复制或从中移动。
关键见解:如果一个对象可能被重用,你就不能窃取它的资源。(If an object might potentially be reused, you cannot steal its resources.)
两个新特殊成员函数:
- Move Instructor (create new from existing r-value)
- Move assignment (overwrite existing from existing r-value)
特殊成员函数的函数签名对比:
1 | StringVector(); // 构造函数 |
移动构造函数与移动赋值
移动构造函数的要点:
- 将其他对象的内容传送到本对象(Transfer the contents of other to this.)
- 尽可能移动而不是复制!(Move instead of copy whenever possible !)
- 让其他对象处于未确定但有效的状态(Leave other in an undetermined but valid state.)
- 强烈推荐:将其设置为class的默认值(Highly recommended: set it to the default value of class)
一个代码例子:
1 | class Axess { |
虽然以上代码是用移动构造函数和移动赋值的对应函数签名写的,其将rhs绑定到右值,但在对应的函数作用域中其还是一个左值(因为能通过取地址符找到地址,其有姓名和身份)。代码students = rhs.students;仍然会进行拷贝操作。因而,我们需要将左值变为右值,相应的函数为std::move。对以上代码做修改如下:
1 | class Axess { |
std::move
基本作用:std::move无条件地将变量转换为右值。std::move的关键要点:
- 移动构造函数/赋值运算符必须执行成员移动
- 作为右值值引用的参数实际上是左值
std::move无条件地将表达式转换为右值std::move本身不会移动任何东西- 在
std::move移动对象之后,不再使用该对象
写一个泛型swap函数
基本代码:
1 | int main() { |
答案代码:
1 | template <typename T> |
代码的模拟运行过程如下:
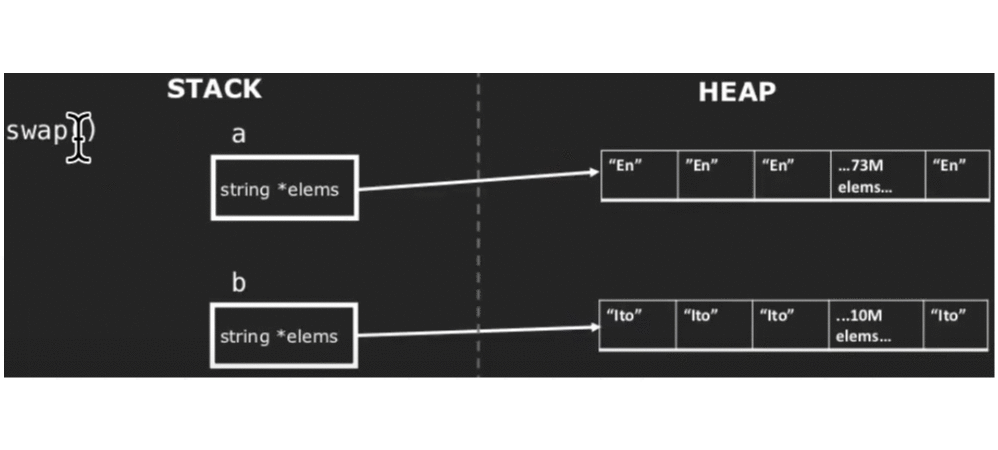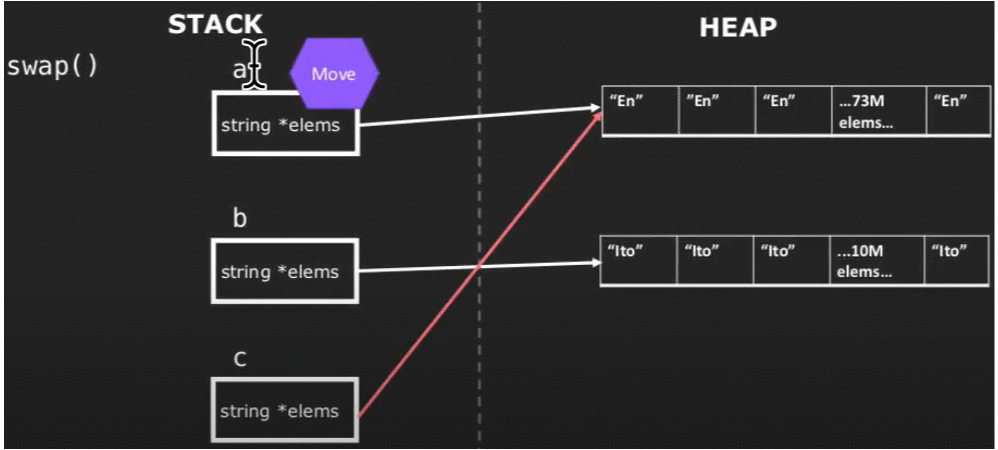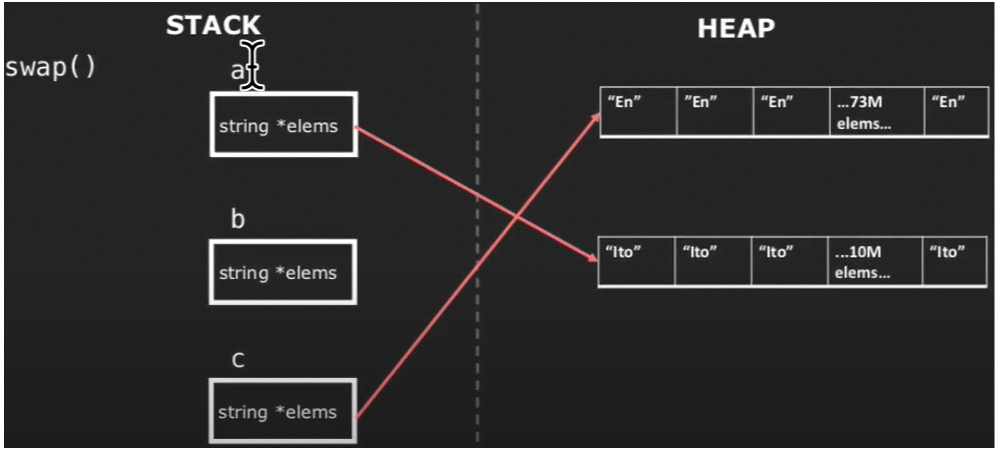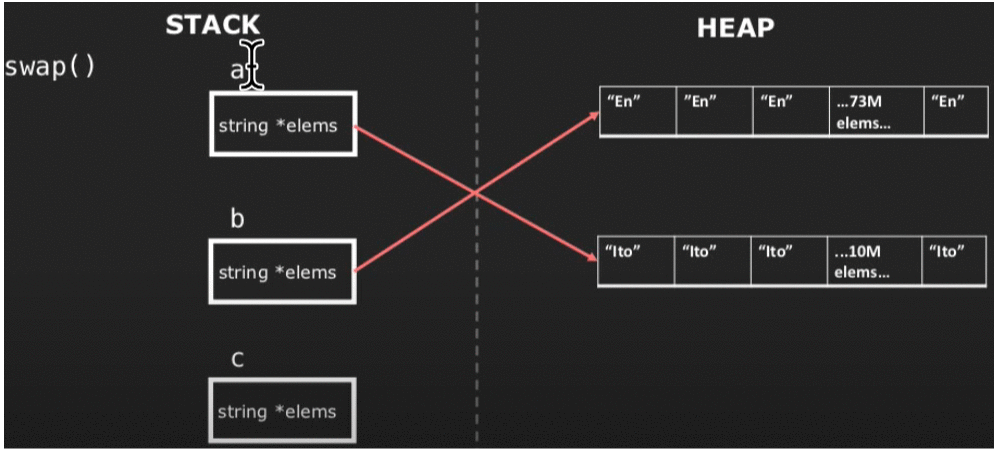
图中的c是我们声明的临时变量。以上模拟过程很明显地体现出了move semantics的本质——被move标记的对象(右值)的资源将会被“偷取”,以避免以往创建多个对象的过程,降低开销。
引入移动构造函数和移动赋值之后的基本规则
- 如果你在显式定义(或删除)复制构造函数、复制赋值、移动构造函数、移动赋值或析构函数中某几个,则应定义(或删除)所有五个特殊成员函数。
- 你定义特殊成员函数其中之一的事实意味着你的类成员之一存在需要解决的所有权问题。
Lecture 14: Inheritance
Namespaces
因为标准库使用通用名称,例如string,max,count等,这使得库的名字很容易发生冲突。大部分现代语言使用namespaces去解决这一问题。
Python例子:
1 | # Generate a random number in Python |
C++例子:
1 | // Count how many times value appears in C++ |
一个更加全面的C++代码例子:
1 |
|
以上代码提示我们最好不要在文件开头使用using namespace std,以避免作用名字冲突的问题。为了兼顾代码的可靠性和易编写性,可以在头文件开头只引入我们所需要的命名空间。但值得注意的是,如果有多个相同的名字,即便在开头引入了对应的命名空间,在实际使用时,也必须加上对应的作用域声明,否则,还是会发生命名空间冲突。
Scope Resolution
为什么我们需要在我们所有的类成员函数前面写ClassName::?
这是为了让便编译器知道我们在为哪个类定义函数!
Inheritance
动机:
1 | void print (ifstream &stream, int i) { |
以上两个函数所做事情都非常相同,那么我们能不能少写一点代码?
尝试1:
1 | template <typename StreamType> |
以上代码可以工作,因为模板使用隐式接口的概念。请注意,没有需要哪些运算符/函数的列表。
如果存在隐式接口,则必须有显式接口。通常只称为接口,这是最简单的继承形式。
Java与C++的代码对比
Java代码:
1 | interface Drink { |
C++代码:
1 | class Drink { |
从以上代码,我们知道C++中没有interface关键字。在C++中,一个类作为一个接口,其必须只包含纯虚函数。 为了实现一个接口,一个类必须定义所有这些纯虚函数。而如果我们确实想在我们的类中定义一些函数时,可以通过虚函数达到这一目的。
尝试2:
1 | void print (istream &stream, int i) { |
只要istream实现了print(作为非虚函数),并且所有类型的流都继承自istream,那么其它流都可以使用这个print函数。此时,我们只需要写一个函数。
备注:没有“虚拟”成员——相反,如果一个成员与继承的成员同名,子类将隐藏父类的成员。代码:
1 | struct A { |
最后是struct跟class的对比。
另外一点需要注意的是, C++中的struct其实几乎等同于类,只是class的成员变量默认是private,struct的成员变量默认是public。参考链接
Lecture 15: Inheritance and Template
Classes
虚函数与纯虚函数
如果一个类至少有一个纯虚函数,则称为抽象类。 (接口是抽象类的子集。)抽象类不能被实例化。代码例子:
1 | class Base { |
类中的纯虚函数被所继承的类实现。非纯虚函数是指,我在当前类实现了一个通用的解决方案,如果我的派生类想要不同的解决方案时,它们可以进行重写非纯虚函数。值得注意的是,正常的函数也可以被重写,但这并不道德。参考
与继承相关的一些定义
基类(Base,又名超类(superclass)或父类(parent)):被继承的类
派生类(Derived,又名子类(subclass,child)):从基类继承的类
构造函数
子类总是调用基类的构造函数。如果未指定,则调用基类的默认构造函数。
析构函数
如果你打算使你的类可继承(即,如果您的类具有任何虚函数),请将您的析构函数设为虚函数!语法:virtual ~Base () {}。否则几乎肯定会有内存泄漏。
参考链接:什么时候析构函数需要定义为虚函数
备注:析构函数是否是虚拟的很好地表明了一个类是否打算被继承。
非虚拟析构函数的例子:
1 | class Base { |
访问说明符
private:只能被这个类访问protected:只能由此类或派生类访问public:任何人都可以访问
但friend关键字声明的友元函数可以访问类的私有成员和保护乘员。(注:虽然类的友元函数有权访问类的所有私有成员和保护成员,但其定义在类的外部。)
一个代码示例:
1 | class Drink{ |
Templates vs Derived Classes
模版是静态多态性,其在编译时消耗资源,实现多态,而派生类是动态多态性,其在运行时消耗资源,实现多态。怎么决定使用哪一个?
使用模版的时机:
- 运行时(runtime)效率最重要
- 无法定义公共基类
使用派生类的时机:
- 编译时(compile-time)效率是最重要的
- 想要隐藏实现
- 不希望代码膨胀(code bloat,模版会在编译时,生成不同数据类型所对应的类,这会增大代码量)
Casting
Casting是指对数据类型进行转换。代码:
1 | // All of these are legal: |
Template Classes
函数模板描述了如何构建一系列外观相似的函数,而类模板描述了如何构建一系列外观相似的类。代码:
1 | // 这里的语法表明Cotainer在没有特殊声明时,默认为std::vector<T> |
Concepts and Constraints(C++20)复习
C++20 引入了Constraints用于在语义层面对模板参数进行约束。而Concept 即为一系列Constraints的符号名称,方便重用Constraints的逻辑。[参考链接](Constraints & concepts - 知乎 (zhihu.com))
例子代码:
1 | template <typename Collection, typename DataType> |
以上代码含有隐式借口,其默认传入的对象有size()函数和[]操作符。如果传入的对象没有对应的函数和操作符,程序将会报出非常难以理解的错误。因而引入了Constraints,它是对模板参数的要求,其允许我们将隐式接口转换为显式的要求。示例代码:
1 | // 1-2行是相应的Constraints |
通过使用Constraints,如果你所传入的参数不满足要求,那么你的代码将会在实际运行之前,通过Constraints那一部分的代码抛出错误。
Concept(概念)是一个谓词,其在编译时评估,是接口的一部分。以上代码的Concept:
1 | template<typename It, typename Type> |
Concepts和Constraints可以与类模板、函数模板和非模板函数(通常是类模板的成员)一起使用。标准库有我们可以使用的Concepts,或者我们可以自己定义。
Concept的详细[参考链接](Constraints & concepts - 知乎 (zhihu.com))。
Lecture 16: RAII and Smart Pointers
导引
一个代码例子:
1 | string EvaluateSalaryAndReturnName (int idNumber) { |
以上代码给出了一个常见的例子,在函数内初始化对象,然后在即将退出时,将其销毁。但实际上,函数并不是总会按照我们预期的进行,反而,函数可能在任意一个节点由于各种原因抛出异常,进而直接退出。比如,执行e.Title()时,如果e没有这一个函数,那么函数就会因为异常而退出。很明显,我们如果通过这种方式退出函数,delete e并没有得到执行。因为new关键字在堆上分配内存,即便当前函数终止远行,它们也仍然会存在于堆上,所以必须自己进行销毁。所以,以上代码可能存在内存泄漏的问题。
更一般的考虑
以下几种相关的C++资源都与资源的占用和归还相关。
| 资源 | 获取方式 | 释放方式 |
|---|---|---|
| Heap Memory | new | delete |
| Files | open | close |
| Locks | try_lock | unlock |
| Sockets | socket | close |
Exception
异常(Exception)是将控制和信息传递给(潜在的)异常处理程序的一种方式。
1 | try { |
强制异常安全
函数可以有四个级别的异常安全:
- Nothrow exception guarantee
- 绝对不抛出异常,例如:析构函数、交换、移动构造函数等。
- Strong exception guarantee
- 回滚到函数调用之前的状态
- Basic exception guarantee
- 异常后程序处于有效状态
- No exception guarantee
- 资源泄漏、内存损坏等
完全避免异常
在某种情况下,其实也可以不使用异常,或者说项目的现有规模并不支持你使用异常时,需要避免使用异常。Google就是如此,它们的大部分代码都没有准备好使用异常,所以它们决定一直不使用异常,并使用其他替代方法(例如错误代码和断言)。[参考链接](Google C++ Style Guide)
We forgot to do it initially, so let’s not bother getting started.
RAII
RAII全称为Resource Acquisition Is Initialization,中文名叫资源获取即初始化,是一种设计理念。其可简单归纳为:所有资源都应该在构造函数中获取,所有资源都应该在析构函数中释放。另一种简称为SBRM,全称为Scope Based Memory Manage,讲课老师喜欢的一种叫法CADRE(Constructor Acquires, Destructor Releases)。RAII将释放资源的代码放到析构函数,这样无论你以何种方式退出函数,资源总是会被释放。因为脱离了当前函数的作用域,对象将不复存在,因而会调用析构函数。
采用RAII的理由
- 对象永远不应该有“半有效”状态。对象应该在创建后可用。
- 析构函数总是会被调用(即使有异常),所以资源总是会被释放的。
一个文件读写例子
1 | void printFile() { |
在以上代码中,资源并未在构造函数中获取或在析构函数中释放。因为以上是先创建文件流对象,之后才使用open()去创建具体对象。同时,close()也只是在析构函数函数外部使用。这是不符合RAII的代码,但这反而是我学刚开始C++时,老师反复强调的写法,先open(),最后再close()。
正确写法如下:
1 | void printFile () { |
在以上代码中,我们直接用构造函数创建对象,同时,文件流对象的析构函数已经写好了释放资源的代码,所以我们没有必要再使用close()。所以,在错误代码里面,代码整体倒也没有内存泄漏的风险,只是最后的close()显得很多余,且不符合RAII通过构造函数创建对象的思想。
一个锁例子
1 | void cleanDatabase(mutex& databaseLock, |
以上代码仍然是传统的思想,先加锁,读写完之后,再释放锁,这次又跟我操作系统老师讲的一样了(其水平极低)。正确的代码如下:
1 | void cleanDatabase(mutex& databaseLock, |
以上代码使得函数无论以何种方式退出,锁总是会被释放。
lock_guard的非模版实现方式
1 | class lock_guard { |
从以上代码可以看出,为了符合RAII这种思想,我们所做的其实就是对资源的申请和释放进行封装,确保对象脱离对应作用域时,其占用的资源会被释放。同时,需要注意的是mutexes不能被复制和移动,因为代码中已经将对应的类方法设置为delete,一个代码例子如下:
1 | class mutex { |
所以,在以上实现lock_guard类时,我们是通过初试化列表来初始化lock_guard的。
总结
在构造函数中获取资源,并在析构函数中释放。这样,类的使用者这就不必担心资源的错误管理。
Smart Pointers
一个CS106B的代码例子:
1 | void rawPtrFn () { |
通过前面的学习,我们知道以上代码存在内存泄漏的问题。C++引入智能指针来解决这个问题。常见的智能指针如下:
std::unique_ptrstd::shared_ptrstd::weak_ptr
注意:auto_ptr在C++98引入,C++11不赞成使用,并且在C++17中被移除。所以,为了向后兼容,应避免使用这个指针。
unique_ptr(C++11)
通过unique_ptr改写以上代码:
1 | void rawPtrEn () { |
unique_ptr不能被复制。因为如果其允许被复制的话,假设复制一次,将会有两个指针指向同一个地址,当第一个指针被销毁时,对应地址的数据已经被析构函数销毁,当第二个指针被销毁时,同样会尝试对同一个地址的数据进行销毁,但是数据在之前已经被销毁过了,所以造成了double free。怎么告知一个类不允许复制?通过删除复制构造函数和复制赋值即可,语法跟前面的mutex类相一致。但是,我们经常希望有多个指向同一个对象的指针。这就引入shared_ptr。
shared_ptr(C++11)
资源可以由任意数量的shared_ptr存储,当资源没有任何一个shared_ptr指向时,对应资源被删除。代码例子:
1 | { |
shared_ptr的实现方式:引用计数(Reference counting)。
基本想法:存储一个 int,用于跟踪当前引用该数据的数字
在拷贝构造函数/拷贝赋值中递增
在析构函数中或被拷贝覆盖时递减
当引用计数达到 0 时释放资源
注意:单个对象的shared_ptr使用仍然成立,这时的引用计数为1。代码:
1 | void rawPtrFn() { |
weak_ptr(C++11)
weak_ptr与shared_ptr 类似,但其对引用计数没有贡献。经常被用于处理 shared_ptr 的循环引用,例如:循环链表。在循环链表中,指向前驱和后继的指针应该要使用weak_ptr,而非shared_ptr。对于一个包含2节点A和B的循环链表,如果使用shared_ptr,每个节点的引用计数都为2,当我们想删除B节点的资源时,我们需要将其引用计数设置为1(这样当脱离作用域时,指针才会释放资源)。为此,我需要将A->next销毁,销毁A->next就需要先将A销毁。但想销毁A时,又需要销毁B->prev,销毁B->prev又需要销毁B,这将陷入循环之中。
通过使用weak_ptr,我们仍可通过A->next和B->prev去访问对应节点,但这些指针并不影响引用计数,也就是它们只有观测权,但其本身并没有共享资源。这样,每个节点的引用计数都为1,当脱离作用域,引用计数减1,资源将得到释放。同时,weak_ptr还可以用于在延迟使用主导权的场景, 比如线程A是重要的,在A完成之后B,C线程可做可不做。这时,B和C就可以使用weak_ptr来控制。
参考链接:
- weak_ptr的作用及应用场景——shared_ptr的循环引用问题_LLZK_的博客-CSDN博客
- C++ 11 创建和使用共享 weak_ptr - 滴水瓦 - 博客园 (cnblogs.com)
- C++11智能指针(weak_ptr) - 简书 (jianshu.com)
- c++的弱引用指针到底是为什么目的引入的?原理是咋回事 - 知乎 (zhihu.com)
unique_ptr与shared_ptr的创建
在前面的例子中,我们的创建方法为:
1 | std::unique_ptr<Node> n(new Node); |
但现在,我们建议使用内置的智能指针创造器,代码:
1 | std::unique_ptr<Node> n = std::make_unique<Node>(); |
相关的三条规则:
函数的参数在函数之前进行评估
每个函数都是“原子的”
而参数可能会以其他方式交错
(最后一条规则现在已经在C++17中得到更改,但我们仍然更喜欢包装函数,例如make_shared具有一些性能优势等。)
代码例子:
1 | // 方式1: f(expr1, expr2) |
基于以上规则的第三条,我们倾向于总是使用std::make_unique<Node>()这一方式。这么做的理由:new返回的指针应该属于一个资源句柄(可以调用 delete )。如果将new返回的指针分配给普通/裸指针,则该对象可能会泄漏。
备注:
在大型程序中,裸露的 delete(即应用程序代码中的删除,而不是专门用于资源管理的代码的一部分)是一个可能的错误:如果您有 N 个 delete,您如何确定您不需要 N +1 还是 N-1?该错误可能是潜在的:它可能仅在维护期间出现。如果你有一个赤裸裸的new,你可能需要在某个地方进行赤裸的delete,所以你可能有一个错误。所以,我们应该警告任何明确的 new 和 delete 使用,同时建议用 make_unique。
注意:在现代C++中,我们几乎从不使用new和delete。这样可以减少很多的内存泄漏问题。
Lecture 17: Multithreading
代码通常是顺序的,而线程(Thread)是并行执行代码的方法。
多线程的一些要点:
- 如果进行多线程编程,请使用原子类型(详细参见
<atomic>库)。 std:: lock guardvs.std:: unique_lock- 常用的3种类型的“锁”/互斥锁:普通(normal)、定时(timed)、递归(recursive)(详细参见链接)。
- 条件变量(Condition variables)允许跨线程通信(详细参见链接)。
std::async是使用多线程的一种方式
一个代码例子:
1 |
|
Further C++ reading
| 书名 | 作者 |
|---|---|
| Accelerated C++ | Andrew Koenig |
| Effective C++ | Scott Meyers |
| Effective Modern C++ | Scott Meyers |
| Exceptional C++ | Herb Sutter |
| Modern C++ Design | Andrei Alexandrescu |
| C++ Template Metaprogramming | Abrahams and Gurtovoy |
| C++ Concurrency in Action | Anthony Williams |
总结
学完这门之后,个人感觉C++的内容确实太多了,而且最近没过几年,还会开会去确定新标准,引入新特性,这可能也算是与时俱进吧。课程是短期内看完了,而且也知道如何去看文档和学习相关的新特性了。后续就是需要多用多写,来加深对C++的理解。