高级计算机网络复习总结
开篇问题:什么叫做高级计算机网络?这个“高级”是什么意思?老师说,网络本来就没有什么高级和低级之分,不是说以前学的就比较低级,这门课讲的就比较高级,只不过是在他上学的时候,课程名就叫这个了,这里只是沿用下来。自己的理解是可能觉得网络的新工作是在传统TCP/IP架构上进行各种修改去做的,所以认为后续的工作会比以往所学的网络要“高级”一点。这节课主要是带着读论文,讲解近十年左右的网络新进展,去了解比较前沿的知识。因为大部分论文其实是10年左右的,也不是网络方面的第一手资料,所以也不是很前沿。但这些论文也确实是有很大影响力的工作,现在每年也还有很多人在研究其中一些论文所开辟的方向,甚至有些论文即将成为HTTP/3的标准。
数据中心网络
FatTree
原论文:A Scalable, Commodity Data Center Network Architecture-2008
1.什么是数据中心网络?数据中心网络所期望的属性是什么?
数据中心:成千上百个电脑的集群,且集群的节点与节点存在大量的信息交换,并且整个集群由一个权威的中心设备进行管理。
期望的属性:
- 可扩展的互连带宽:任意主机可以在其本地网络接口的全带宽下与任何其他主机通信。
- 规模经济效益:能让廉价的,现成的以太网交换机成为大规模数据中心网络的基础。
- 向后兼容:整个系统对运行以太网和IP的主机向后兼容。
2.在数据中心中,传统的三层拓扑是什么样的?它的局限是什么?
传统的三层拓扑通常可以分为三层:分别为接入层,汇聚层和核心层。
局限:
- Oversubscription。Oversubscription较低,主机跟主机之间的通信并不能完全利用网络的带宽。
- 多路径路由。现有基于ECMP的多路径路由技术,会在流之间执行静态负载分配。在进行分配决策时,没有考虑流带宽,即使是简单的通信模式,也可能导致oversubscription。此外,目前的ECMP实现将路径的多样性限制在8-16,这通常比为大型数据中心提供高等分带宽所需的多样性要少。此外,路由表项的数量会随着考虑的路径数量的增加而成倍增加,这会增加成本,也会增加查找延迟。
- 成本。为了维持一定的Oversubscription,成本会随着规模急剧增加。
3.FatTree跟以往传统的设计有什么不同?
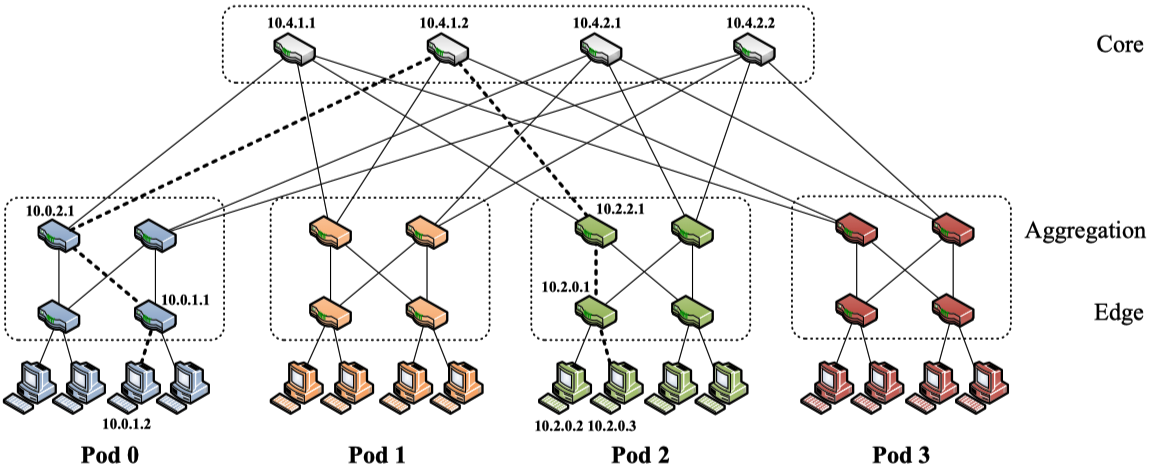
拓扑上:仍然分为三层:核心层,汇聚层,接入层,但其所用到的交换机均为相同端口数量的普通设备。
- 每台交换机都有k个端口;
- 核心层为顶层,一共有(k/2)^2个交换机;
- 一共有k个pod,每个pod有k台交换机组成。其中汇聚层和接入层各占k/2台交换机;
- 接入层每个交换机可以容纳k/2台服务器,因此,k元Fat-Tree一共有k个pod,每个pod容纳k*k/4个服务器,所有pod共能容纳k*k*k/4台服务器;
- 任意两个pod之间存在k条路径。
地址上:全部是本地IP,且根据Pod进行设计独特设计。
- 所有IP地址都在私有的10.0.0.0/8块内网络。
- pod交换机的地址是10.pod.switch.1,
pod表示交换机的序号(在[0,k−1]中),
switch表示该交换机在pod中的位置(在[0,k−1]中,从左到右,从下到上)。 - 核心交换机的地址形式为10.k.j.i,
j和I表示交换机在(k/2)^2核心交换机网格中的坐标(i,j在[1,(k/2)]中,从左上角开始)。
路由算法上:
- 两阶段路由表。前缀表向下(本pod内部)转发包,后缀向上(其他pod)转发包。
- 通过路由表的设计,能够平均地分发流量。同时,这样设计路由表能够让同一个目的IP的数据包从同一个路径转发,避免了数据包的重新拍序。(举个例子,如果10.0.1.2和10.0.1.3上的数据包都想要发送到10.2.0.3,除了刚开始到low-level边缘交换机的路径不同,之后它们数据包所走的路径全都是一样的。但这么说感觉没道理,因为不同主机上通信内容根本不一样,重不重新排序都没关系。只能说自己用同一子网的不同源IP地址对应相同目的IP地址,推出来的路径是这样。而对于同一主机来说,同一主机走的数据包都一样,这样的话,不需要重排倒是很有用的。)
- 路由表生成算法根据自己设计的算法生成,而非以往的,由switch主导的路由表生成。
PortLand
原论文:PortLand: A Scalable Fault-Tolerant Layer 2 Data Center Network Fabric-2009
1.为什么现存的L2和L3技术不能满足云数据中心的R1-5?
根据多核处理器、终端主机虚拟化和规模商品的发展趋势,未来的单站点数据中心将拥有数百万个虚拟端点,这即是云数据中心。在这种情况下,现有的第2层和第3层网络协议面临着很多缺陷:缺乏可伸缩性、管理困难、通信不灵活、对虚拟机迁移的支持有限。
R1和R2:对2层结构(fabric)来说,可以支持迁移。但是迁移的交换机需要通过广播来学习MAC地址,当网络规模很大的时候,网络的带宽将主要被用来广播,无法进行正常的通信。对3层结构来说,当主机迁移新的网络时,需要进行IP配置,而配置IP的时候,IP地址就发生了变化,导致之间业务的中断。
R3:对于2层结构来说,当网络规模很大时,需要很大数量的MAC转发表项。这对当前的交换机硬件来说,并不可行。
R4:对于2层和第3层来说,R4都是较难满足的。因为在路由收敛过程中可能会出现转发环路。2层协议可以通过使用一棵生成树来避免这种循环,但这非常低效,也可以通过引入一个附加TTL报头来容忍这种循环,但这并不兼容。
R5:R5需要有效的路由协议,能够将拓扑变化快速传播到所有感兴趣的点。但现有的第2层和第3层路由协议,如ISIS和OSPF,都是基于广播的,每个交换机更新都发送给所有交换机。在效率方面,这类协议的广播开销可能需要配置等价的路由区域,这又不满足R2了。
2.什么是PMAC地址?
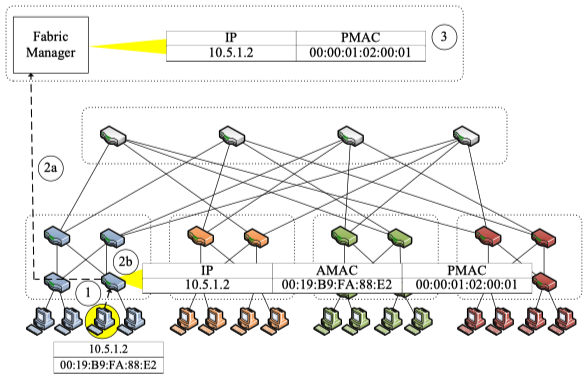
PMAC:Positional Pseudo MAC Address,位置标识的伪MAC地址,跟实际的主机MAC(AMAC)地址相对应。
PMAC是PortLand边缘交换机所需要学习的一个信息。PMAC编码主机的在网络拓扑中的位置信息,即在哪个Pod,哪个交换机端口连进来的主机上的第几个虚拟机。
PMAC是一个48-bit数,可分为pod:position:port:vmid。
pod(16 bits):主机所连接边缘交换机的pod序号。
position(8 bits):主机所连接边缘交换机在pod中的位置。
port(8 bits):主机所连接边缘交换机的port序号。
vmid(16 bits):虚拟机在物理服务器上的序号。
在PortLand网络中,作者用PMAC来转发数据,当转发到主机的前一跳交换机时,把PMAC改为AMAC,将数据交付给对应主机。
为了应用PMAC,这里会修改ARP协议,用PMAC替代AMAC,来代表虚拟机,进行数据转发。
3.位置发现(Location Discovery)是什么?
位置发现是PortLand所提出的一个协议,用于让交换机学习自身处于什么位置,以及对应的Pod编号等信息。
在这个协议中,PortLand的交换机会定期从它们的所有端口向外发送LDM包,并且从所有端口接收LDM包。其包含:
- Switch id。每一个交换机在整个网络中的独特编号。类似MAC地址。
- Pod number。FatTree中,交换机的Pod编号。
- Postion number。FatTree中,边缘交换机的编号。
- Fat Tree’s Level。即核心,汇聚和边缘交换机的区别。
- Up/Down。记录这个包是向上发送的,还是向下发送的。
通过定期收发LDM包,每个交换机就逐渐能弄明白自己处于整个网络拓扑中的什么位置。
4.PortLand是什么满足R1-R5的?
作者认为云数据中心应该满足五个需求,这是他自己提出的。为了满足这些需求,他在这篇文章中进行了阐述。
R1:虚拟机可以迁移到任意物理机。引入PMAC,每个虚拟机都对应一个PMAC地址。在虚拟机迁移过程中,主机将新PMAC通过ARP发送给其他与该虚拟机通信的主机。对应主机就会与虚拟机迁移位置的主机通信,转发数据。同时,由于Fabric Manager对主机IP和PMAC的管理,虚拟机在迁移过程中只会更改PMAC,IP地址没有发生变化,因为迁移过程中的通信也就不会中断。
R2:部署之前不需要配置。引入LDP(Location Discovery Protocol)协议,交换机之间可以通过定期收发LDM包,自主学习PortLand的拓扑信息,为转发数据包做铺垫。
R3:任何两个主机之间能够有效地进行通信。使用所有花费相同的路径,用ECMP进行负载均衡。
R4:没有转发环路。在PortLand中,交换机通过PMAC的信息进行转发数据,主机之间的数据都是先向上走,再向下走。主机之间的路径是确定的(不考虑向上走的负载均衡),并不存在向上,向下,再向上,可能会导致转发环路的问题。
R5:能够迅速地检测故障,使得故障不影响当前网络的通信(不包含修复,这是之后的事情,这里只是检测网络故障,然后绕开它)。通过结构管理器(fabric manager)实现。Fabric Manager维护当前网络设置的软状态(每一段时间接收到网络主机的拓扑报告,因为需要更新时间,这个拓扑可能跟当前最新时刻的网络拓扑是不相符的。)。当链路存在故障之后,对应交换机无法接收LDM包,会向上报告给Fabric Manager。Fabric Manager再向所有交换机报告链路故障位置,交换机会重新计算拓扑路径,以转发数据包。
网络测量
Flow Radar
原论文:FlowRadar: A Better NetFlow for Data Centers-2016
1.Bloom filter是什么?False positive错误的来源和概率?
Bloom filter是一种数据结构,包含一个比特向量和多个哈希函数,它能够用来近似地判断某个元素是否在某个集合中。其优点在于查询效率高,占用空间少,但缺点是随着存入元素的增多,误判的概率会随之增大,而且不支持删除操作。
因为布隆过滤器是通过检查一个元素经过多个Hash映射到布隆过滤器上的bit位是否全为1来判断其是否存在于集合之中,随着存入元素的增多,即便一个元素并不存在于对应集合中,但其经过Hash映射的对应bit位却被其他元素的Hash映射置为1,就会导致误判。
设m布隆过滤器的bit位数,k为哈希函数个数。当已经插入的元素个数为n时,特定bit位仍然为0的概率为:$( 1-\frac{1}{m} )^{kn} \approx e^{-kn/m}=f $,对于一个不存在的元素,其可能被判断存在集合中的概率:$(1-f)^k=(1-e^{-kn/m})^k$。为了最小化False Positive的概率,可以得到最优的哈希函数个数:$k=\frac{m}{n}ln2$。
2.FlowRadar的基本设计
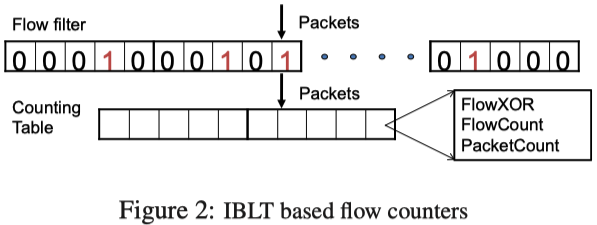
Packet Processing(Encode):当接收到一个包时,首先用flow filter(其实就是一个布隆过滤器)去检查这个流是否已经存在于Flowset中。如果是一个新流,就更新计数表(counting table),异或flow ID和FlowXOR字段,增加FlowCount和PacketCount;如果是一个已经存在的流,只增加PacketCount。
Single Decode:首先检查FlowCount为1的单元,进而就可以找到这个单元里Flow对应的ID和包数,这个ID的Flow就得到了解码。下面对这个解码Flow执行Flow filter的哈希函数,去定位跟它相关的其他Flow fliter单元,对这些单元对应的Counting table的FlowXOR字段执行异或操作,FlowCount和PacketCount都减去解码Flow的对应数字,得到Single Decode解码出来的单个Flow和剩下Flowset。这样就认为是做了Single Decode,其主要是先解码单个Flow。
FlowDecode&CounterDecode(Network-wide Decode):利用网络上多个交换机的信息,每个交换机都会有一个Flow filter和对应的Counting table。
FlowDecode:对于任意两个邻居的Single Decode,检查一方Single Decode解码的所有单个Flow是否在另一方的Flowset中,如果存在,就将这些单个Flow从另一方的Flowset中删去(包含FlowXOR等字段)。对两者都进行检查之后,都分别调用Single Decode,去看能否从这两个邻居的Flowset中解码更多信息。
CounterDecode:虽然可以使用FlowDecode轻松解码流,但这不能解码它们的计数器。这是因为由于丢包和动态包的原因,同一流在A和B处的计数器可能不相同。但从FlowDecode的过程中,我们可能已经知道一个编码Flowset中的所有流。也就是说,在每个单元中,我们知道单元中的所有流以及这些流计数器的汇总。假设流集中有mc个单元和n个流,总共有mc个方程和n个变量。这意味着需要解MX = b,其中X是n个变量的向量,M和b由上述方程构建。用Matlab即可进行加速求解。
单元(cell)指Flow filter中的格子个数。
Elastic Sketch
原论文:Elastic Sketch: Adaptive and Fast Network-wide Measurements-2018
1.Hash table和CM(count-min) sketch
Hash table:Hash table为一个有B个桶的表,每个桶的序号依次为{0,1,…,B-1},每个桶包含Flow ID,FLow的包数等信息。为了将流映射到hash表,还需要一个hash函数h( ),一个流可以被编号为h(f)%B的桶追踪。当想要获得对应流的信息时,计算h(f)%B,从对应序号的桶中拿出信息。
CM sketch:d个独立的hash函数,每个hash函数的计算值会映射到长度为w的Counter。根据hash函数数目和Counter数目,可以构建出一张d行,w列的表。当到达一个流时,依次计算d个hash函数的值并更新对应的Counter。当估计流时,选择流不同hash映射的Counter最小值。
Hash table和CM sketch都存在错误估计的可能。
2.Elastic Sketch的基本设计
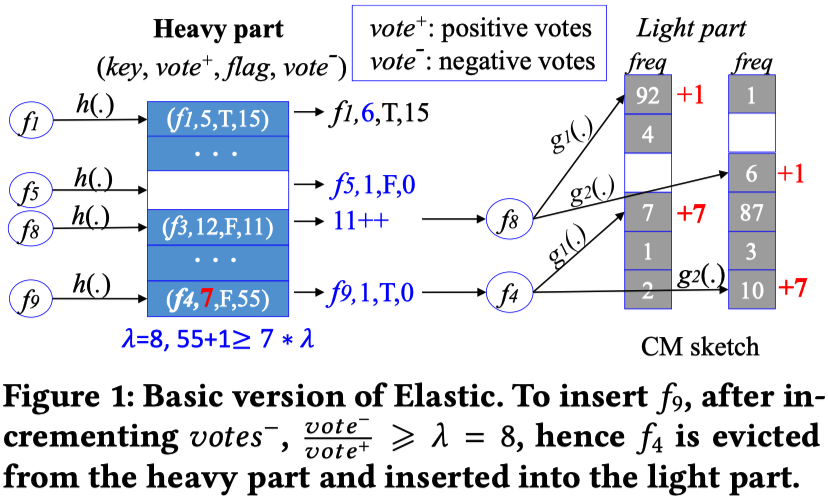
整体的数据结构分为两大块:Heavy part和Light part。
Heavy part:用来计算大象流,数据结构为一个hash表,每个hash表的桶为一个4元组:$(Flow ID,vote^+,vote^-,flag)$。
Light part:用来计算老鼠流,数据结构为一个CM sketch。
Insert operation:当接收到一个流flow f之后,首先计算hash函数,将其映射到对应的桶,假设桶中四元组为$(f1, vote^+, flag1, vote^-)$,CM sketch转移阈值$\lambda$。分类讨论:1) 当桶为空时,$insert(f, 1, F, 0)$;2)当桶不为空,f=f1时,$vote^+$的值加1;3)当f≠f1时,先将$vote^-$的值加1,如果$vote^-/vote^+ < \lambda$,将f插入CM sketch,对应Counter值增加1;4)当f≠f1时,先将$vote^-$的值加1,如果$vote^-/vote^+ \geq \lambda$,将f1插入CM sketch,对应Counter数增加$vote^+$,并将桶的四元组设置为$(f, 1, T, 0)$。(论文的$(f, 1, T, 1)$应该写错了)
Query operation:当流f不在Heavy part中时,在Light part中估计它;当流f在Heavy part中,1)如果对应元组的flag为F,返回$vote^+$;2)如果对应元组的flag为T,返回$vote^+$和CM sketch计数结果的和。2)为什么要返回两者之和是因为在一个流f满足阈值不等式之前,f一直在使得$vote^-$增加,并被移入Light part,即流f的一些计数在其被填入Heavy part之前,被移动到了Light part)。
3.可用带宽的适用性(Adaptive to available bandwidth)
设计Sketch compressing and merging。
4.流大小分布的适用性(Adaptive to flow size distribution)
设计Copy operation。
个人认为3和4更像是从Elastic Sketch的实际问题出发,设计出的一些小Trick,并没有深入了解。
网络协议
BBR
原论文:Congestion-Based Congestion Control-2016
1.为什么基于丢包(loss-based)的拥塞控制算法会导致大延迟和低吞吐?
在上世纪80年代,传统TCP拥塞控制算法将丢包作为发生拥塞的信号。这在那个年代是正确的,而当网卡的速率从Mbps级别进化为Gbps级别,内存从KB级别进化到GB级别之后,丢包与拥塞的关系变得不那么紧密了。
当瓶颈链路的缓存较大时,这些基于丢包的拥塞控制算法将填满缓存,造成了缓冲区膨胀,队列增长,导致较大的延迟;当瓶颈链路的缓存较小时,这些算法会又将丢包作为发生拥塞的信号,从而降低速率导致了较低的吞吐量。
另一种理解:因为基于丢包探测的算法总会使inflight的数据量达到BDP+BtlBufSize这个状态,在现代的路由器中由于缓存很大,相当于把物理链路人为的拉长了,使数据传输的时延变大,即RTT变大。
2.理解BBR给出的原理图
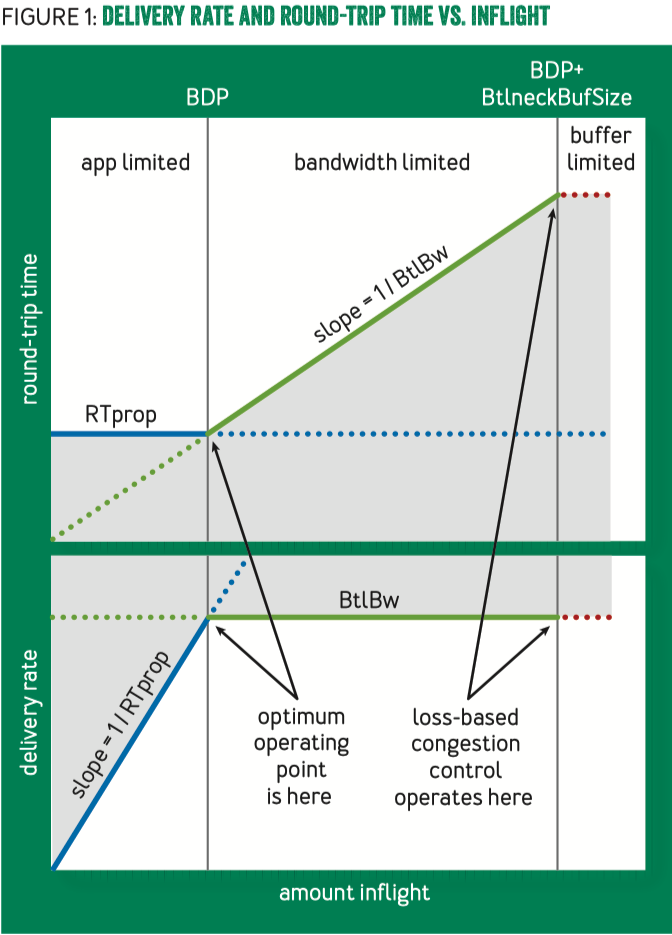
图中的两个关键点
两个关键点是BDP(Bandwidth-Delay Product)点和BDP+BtlneckBufSize点。BDP指带宽和延迟的乘积,BDP+BtlneckBufSize指BDP加上瓶颈缓冲区容量。
BDP = RTprop × BtlBw,其实际含义是总的发送了,但还没有确认的数据(data in flight),RTprop(Round-Trip propagation time):往返传输时间,BtlBw(Bottleneck Bandwidth):瓶颈带宽(传输最慢的链路带宽)。理解:将网络路径看作物理管道的话,则RTprop即为管道长度,而BtlBW是管道最窄处的直径,BDP就可看作是管道的容量(瓶颈容量)。
关键点的左侧和右侧分别有什么行为?观察到什么现象?原则上怎样调整?
两个关键点可将上图分为三部分区间。
在BDP点左侧区间,客户端发送数据没有填满发送管道,称为应用受限(app limited)区域。(也可以认为是数据包发送速率没有达到瓶颈带宽BtlBw)。
在BDP点和BDP+BtlneckBufSize点的中间区间,发送数据达到链路瓶颈容量,但还没有超过瓶颈容量+缓冲区容量。应用发送数据主要受带宽限制,因此称为带宽受限(bandwidth limited)区域。
在BDP+BtlneckBufSize点的右侧区间,发送数据超过瓶颈容量+缓冲区容量,多出来的数据会被丢弃。会冲去的大小决定了丢包的多少,因此称为缓冲区受限(buffer limited)区域。
从图中可以看出,传统基于丢包的拥塞控制算法是基于BDP+BtlneckBufSize点的。当缓冲区被填满,发生丢包时,基于丢包的拥塞控制算法才会开展行动,缓解拥塞。而实际上,数据包已经在缓冲区排队了,同时,现在的缓冲区存储已经比链路BDP还要大了,这种使得“丢包”和“拥塞”并不匹配。这种缓冲区队列的增长将导致秒级的延迟。
拥塞实际上对应为数据包在缓冲区不断地增长,在图中即为总发送数据量不断向右侧偏离BDP点的行为,拥塞控制就应该转而去设计控制这种偏离的算法和方法,而非基于丢包去控制拥塞。本文的BBR算法即针对BDP点去进行拥塞控制,使得缓冲队列始终不会过长,以降低延迟并增大吞吐。
3.BBR算法细节
怎么估计RTprop和BtlBw?
BtlBw和RTprop在整个连接的生命周期中可能是动态变化的,所以需要实时地对它们进行估计。
目前TCP为了检测丢包,必须实时地跟踪RTT的大小(从发送数据到收到这个包的ACK的时间),在任意的时刻t,有$RTT_t=RTprop_t+\eta_t$,其中,$\eta_t\geq0$表示路上因为积压,接收方延迟应答策略等因素而引入的“噪声”;$RTprop$是往返传输时延。前面已知,RTprop是路径的一个物理特性,只有当路径发生变化时它才会变化。由于路径变化的时间尺度远大于RTprop,因此在时刻T,RTprop的一个无偏估计是:
$\hat{RTprop}=RTprop+min(\eta_t)=min(RTT_t), {\forall}t{\in}[T-W_R,T]$
其中,$W_R$为时间窗口大小,其持续时间一般是几十秒到几分钟。
理解:一段时间内的最小RTT(可测量),就是这条路径(在一段时间内)的往返传输延迟。因为存在噪声,测得的RTT一定是小于$RTprop$的,所以这里取一段时间的最小值,去不断逼近想要的$RTprop$。
TCP 规范中并没有要求跟踪BtlBw,但可以通过跟踪传输速率(delivery rate)来得到一个对瓶颈带宽BtlBw的好估计。当应答包(ACK)到达发送端时,其中除了包含 RTT 信息,还包含包离开时的inflight data传输情况。已传输的数据量除以传输时间,就是发送和应答之间的平均传输速率:$deliveryRate=\Delta delivered/\Delta t$。又因为:
- 这个速率一定
<= bottleneck rate; - 到达数据量$\Delta delivered$已经知道了,因此接下来需要确定的是$\Delta t$,而 $\Delta t \geq true\ arrival\ interval$;
- 因此,$deliveryRate \leq true\ delivery\ rate$,也就是估计出的传输速率,不会超过真实瓶颈带宽,后者是前者的上限。
因此,传输速率在一段时间窗口内的最大值(windowed-max),是BtlBw的一个无偏估计:
$$ \hat{BtlBw}=max(deliveryRate_t),\ {\forall}t\ {\in} [T-W_B,T]$$
其中,$W_B$为时间窗口大小,一般是6-10个RTT。
直观上的解释:一段时间内的链路最大传输带宽(可测量),就是这条链路的瓶颈带宽。
怎么处理瓶颈带宽(BtlBw)的增加或减少?
当瓶颈带宽降低时,通过一个窗口时间的BtlBw过滤器检测,降低BDP,更慢地发送数据。当瓶颈带宽增加时,做实验,更快地发送数据,去验证BtlBw的增加。
怎么处理Round-trip传播时延的增加或减少?
当Round-trip传播时延降低时,通过一个窗口时间的RTprop过滤器检测,增大BDP,更快地发送数据。当Round-trip传播时延增加时,做实验,更慢地发送数据,去验证RTprop的降低。
4.ProbeBW和ProbeRTT状态的理解
ProbeBW:
BBR将它的大部分时间的在外发送数据都保持为一个BDP大小,并且发送速率保持在估计的BtlBw值,这将会最小化时延。但是这会把网络中的瓶颈链路移动到BBR发送方本身,所以BBR无法察觉BtlBw是否上升了。
BBR周期性的在一个RTprop时间内将pacing_gain设为一个大于1的值,这将会增加发送速率和在外报文。如果BtlBw没有改变,那么这意味着BBR在网络中制造了队列,增大了RTT,而deliveryRate仍然没有改变。(这个队列将会在下个RTprop周期被BBR使用小于1的pacing_gain来消除)。
如果BtlBw增大了,那么deliveryRate增大了,并且BBR会立即更新BtlBw的估计值,从而增大了发送速率。通过这种机制,BBR可以以指数速度非常快地收敛到瓶颈链路。
ProbeBW具体做法:
使用一个包含pacing_gain的8阶段循环:5/4,3/4,1,1,1,1,1,1,每个循环持续一个RTprop。
首先使用大于1的pacing_gain去探测更多带宽
如果瓶颈带宽增加,那么发送速率增加和更大的BtlBW采样就会被测量,并更新
$BtlBw=max(deliveryRate_t)$
否则,在瓶颈处排起队列
当pacing_gain小于1时,清空队列。(降低发送速率,以清空队列)
注:cwnd_gain总是保持2这个恒定值。
ProbeRTT:
ProbeBW的pacing_gain周期性变化,使大flow将带宽匀给小flow, 最终每个 flow 都得到一个公平的带宽份额。整个过程非常快,通常持续几个 ProbeBW 周期。
但如果某些flow短时间地积压,后来者会过高估计 RTProp,可能导致一段时间内的不公平,即收敛时间超出几个ProbeBW周期。所以需要通过ProbeRTT,将flow的状态移动到BDP左侧,以学习真正的RTT。
ProbeRTT具体做法:
当RTProp的估计值超过10s秒钟未被更新时(例如,没有测量到一个更低的RTT), BBR 进入ProbeRTT,并将cwnd降低至一个非常小的值(4个包)。在经过至少200ms之后,如果没有更小的RTT被观测到,这意味着在进入ProbeRTT之前没有队列,就进入Startup状态;否则,进入ProbeBW状态。
理解:
大flow进入ProbeRTT之后,会从积压队列中消耗drain很多包,因此一些flow就能观测到一个新的RTprop(new minimum RTT)。这使得它们的RTprop估计在同一时间过期,因此集中进入ProbeRTT状态,这会进一步使积压的数据更快消化,从而使更多flow看到新的RTprop,以此类推。这种分布式协调(distributed coordination)是公平性和稳定性(fairness and stability)的关键。
- BBR 的期望状态是瓶颈队列零积压(an empty bottleneck queue) ,并围绕这个目标不断同步 flow;
- 基于丢包的拥塞控制,期望状态是队列的定期积压和溢出( periodic queue growth and overflow,这会导致延迟放大和丢包),并围绕这个目标不断同步 flow。
整体BBR算法可通过一个状态机描述,其图如下:
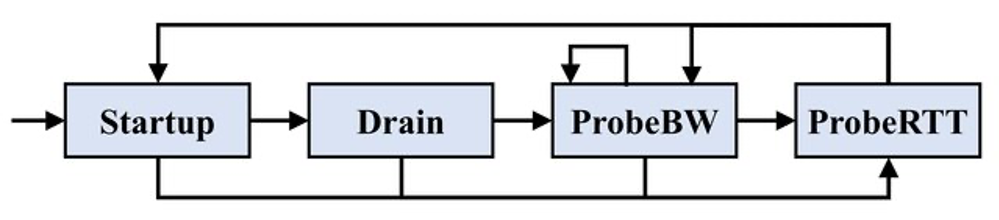
- Startup State
- 目的:快速填满管道
- 将pacing_gain和cwnd_gain设置为2/ln2,
发送速率每轮翻一番。
如果交付率实际导致的增长低于25%,那么估计已经到达BtlBw并进入Drain State。
- Drain State
- 将pacing_gain设置为ln2/2。
- 当飞行中的数据包大小与估计的BDP匹配时,进入ProbeBW状态。
参考:
COPE
原论文:XORs in The Air: Practical Wireless Network Coding-2006
1.Butterfly网络理解
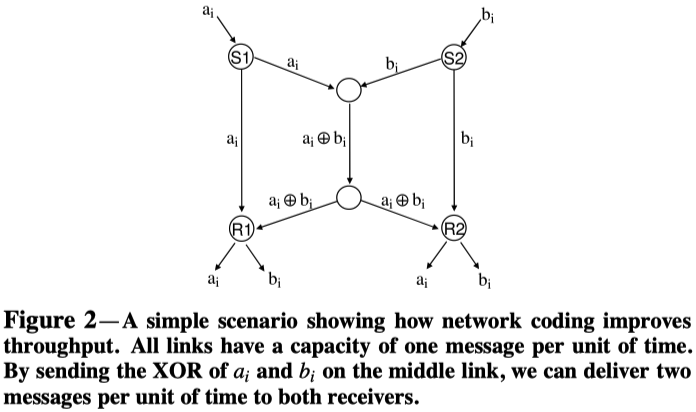
理解就如图标题所描述的那样。在Butterfly网络中,每个链路只能在每个时间单元发送一个信息。通过中间链路发送ai和bi的XOR,并在接受端R1和R2进行解码,可以实现在一个时间单元内向接收端发送两个数据。
2.以下几个例子中的Coding gain和Coding+MAC gain理解
Coding gain定义:在发送同一组包时,不编码方法所需的传输次数和使用COPE所需的最少传输次数之比。
Coding+MAC gain定义:使用COPE时,其瓶颈的排放(drain)速率和不使用COPE的排放比率之比。
- Alice-and-Bob-Topology
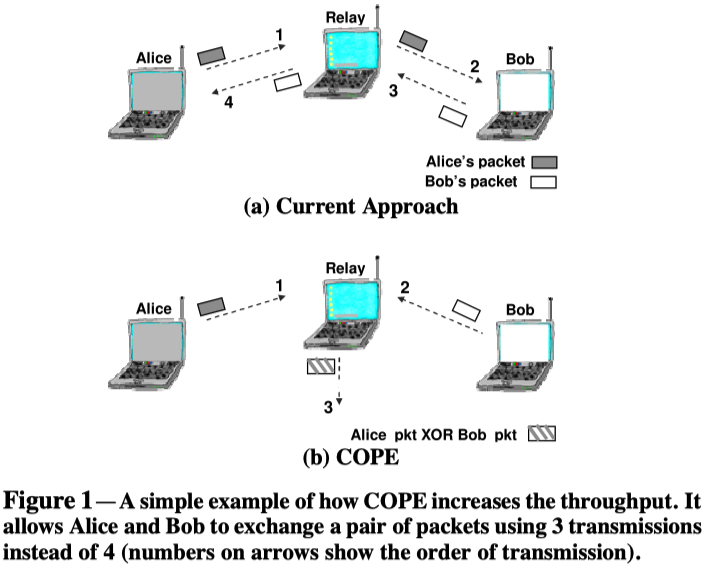
Coding gain:4/3=1.33
Coding+MAC gain:2/1=2
使用Alice-Bob场景解释Coding+MAC gain。因为试图公平,MAC在3个竞争节点之间平均分配带宽:Alice,Bob和路由器。然而,在没有编码的情况下,路由器需要传输的数据包数量是Alice或Bob的两倍。路由器从边缘节点接收到的流量与其mac分配的流量不匹配,使路由器成为瓶颈;边缘节点传输的数据包有一半被丢弃在路由器的队列中。COPE允许瓶颈路由器以两倍的速度对数据包进行异或处理,从而使网络的吞吐量增加一倍。因此,Alice-Bob拓扑的Coding+MAC增益为2。
直观理解:原先需要中继路由器建立两条发送链路,而通过COPE只需建立一条发送链路。这两者之比即为Coding+MAC gain。
- X-topology
拓扑描述:n1向n2发,n4向n5发,发送端都通过n3中继。n5可以听到n1,n2可以听到n4。n3结合两个发射包。
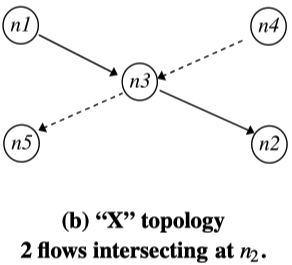
Coding gain:4/3=1.33
Coding+MAC gain:2/1=2
- Cross-topology
拓扑描述:n1和n3交换包,n4和n5交换包。n1和n3可以听到n4和n5,反之亦然。整体的包都通过n2中继和结合。
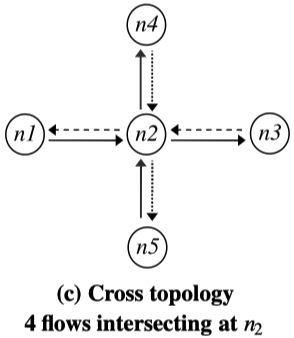
Coding gain:8/5=1.6
Coding+MAC gain:4/1=4
理解:原先每对收发节点之间都需要单独通过两次链路传输发包,而使用COPE,n2可以将4个发送端的包进行XOR,再进行1次广播,在各个接收端即可进行XOR解码,将总传输次数将为5。(因为n1知道其自己的发送信息,还可以听到n4和n5,其他节点也是类似的。)
3.编码算法理解
包编码算法的三个原则:
绝不推迟包的发送。
当信道是可用的,如果2个及以上的单包(没有XOR的包)可以被编码,XOR他们并发送;
如果没有编码机会,不进行等待,将未编码的包放到队列头部。
更倾向于XOR有相似长度的包。
不对前往同一个下一跳或由编码节点生成的数据包进行编码。
包编码算法:

首先,编码算法会根据数据包大小,为每个邻居维持两个虚拟队列。(阈值为100字节)
之后,从路由器的FIFO输出队列中取出第一个包。如果是大数据包,对于每个邻居,检查大数据包虚拟队列的第一个包是否可以被XOR。如果是小报文,对于每个邻居,检查小数据包虚拟队列的第一个包是否可以被XOR。对每个邻居,需要确保$P_D\geq G$,才会将当前包也XOR进去。(假设我们已经决定将n-1个包一起异或,正在考虑将第n个包一起异或。编码算法现在检查,对于每个下一跳邻居,在第n个包与其他包异或后的解码概率$P_D$是否保持大于阈值G(默认值G = 0.8)。如果满足上述条件,则进行编码,同时每个下一跳解码其数据包的概率至少为G。)
算法中的邻居解码概率估计:
- 100%肯定的情况。收到邻居的接收报告或者邻居为报文的前一跳。
- N个包编码在一起的情况。下一跳听到的数据包$i$的概率记为$P_i$,则邻居解码原生数据包的概率等于它已经听到所有n-1个原生数据包一起XOR的概率,表示为:$P_D=P_1×P_2×…×P_{n-1}$。(直观理解就是所有下一跳听到数据包$i$概率的累乘,当这个乘积大于等于阈值G时,我们才能比较确信接收端具有解码所需要的其他元素数据包。)
解码概率理解:我们希望确保数据包所指向的每个邻居都有很高的概率解码其想要的原生数据包。因此,对于其输出队列中的每个包,我们的中继节点估计其每个邻居已经听到该包的概率。(这里的“该包”是编码序列中用来XOR的一个个原生数据包,如果数据接收端已经接收到很大一部分这样原生数据包,把这些原生数据包跟传过来的编码数据包进行XOR,即可得到未知的,想要的原生数据包。)
有时节点可以确定答案,例如,当邻居是包的前一跳,或接收到邻居的接收报告。当上述两个都不为真时,节点利用路由协议计算的交付概率。它将数据包的前一跳和该邻居之间的传递概率作为邻居拥有该数据包的概率估计。然后,节点使用这个概率估计来确保被编码的包被它们所有的下一跳以高概率解码。
为什么需要包含原生数据包才能解码,因为算法基于XOR概念。所以,需要原生数据包,才能将编码数据中的原生数据包XOR掉,去得到剩下的数据包。
同时还要明确原生数据包(Naives)这一概念,原生数据包(Naives)是用来XOR生成编码序列的一个个包。
理解以下图例:
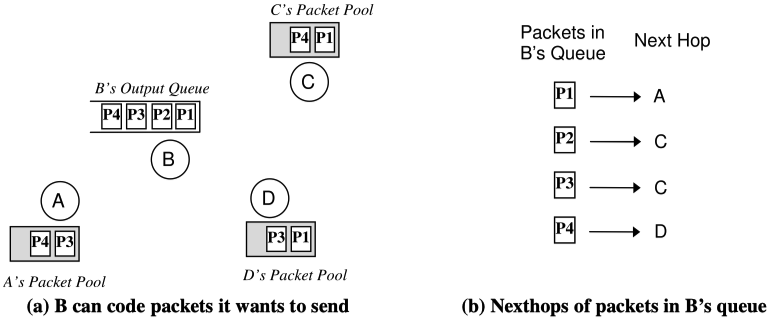
B端运行编码算法,原生数据包Naives = {P1},下一跳Nexthop = {A},此时数据包内容P=P1。
- 对于队列中,发给邻居C的P2,P1⊕P2不能被A解码,所以跳过;
- 对于队列中,发给邻居D的P4,P=P1⊕P4,Naives = {P1,P4},Nexthop = {A, D};
- 对于另一条队列中,发给邻居C的P3,P=P1⊕P4⊕P3,Naives = {P1,P4,P3},Nexthop = {A, D, C}。
MPTCP
原论文:Design, implementation and evaluation of congestion control for multipath TCP-2011 & Decoupled from IP, TCP is at last able to support multihomed hosts-2014
1.MPTCP的好处是什么,它是如何工作的?
MPTCP将传统的单个TCP传输扩展为多路径TCP传输,这样当一条TCP链路发生拥塞或者其他故障之后,其他子流仍可继续传输数据,保持连接不中断。对于日常连接WiFi的场景,当WiFi质量变差时,可以自适应地选择移动数据传输数据,并保持连接不断。在有个多网卡的服务器上,可以提高网络的可用性和吞吐量。
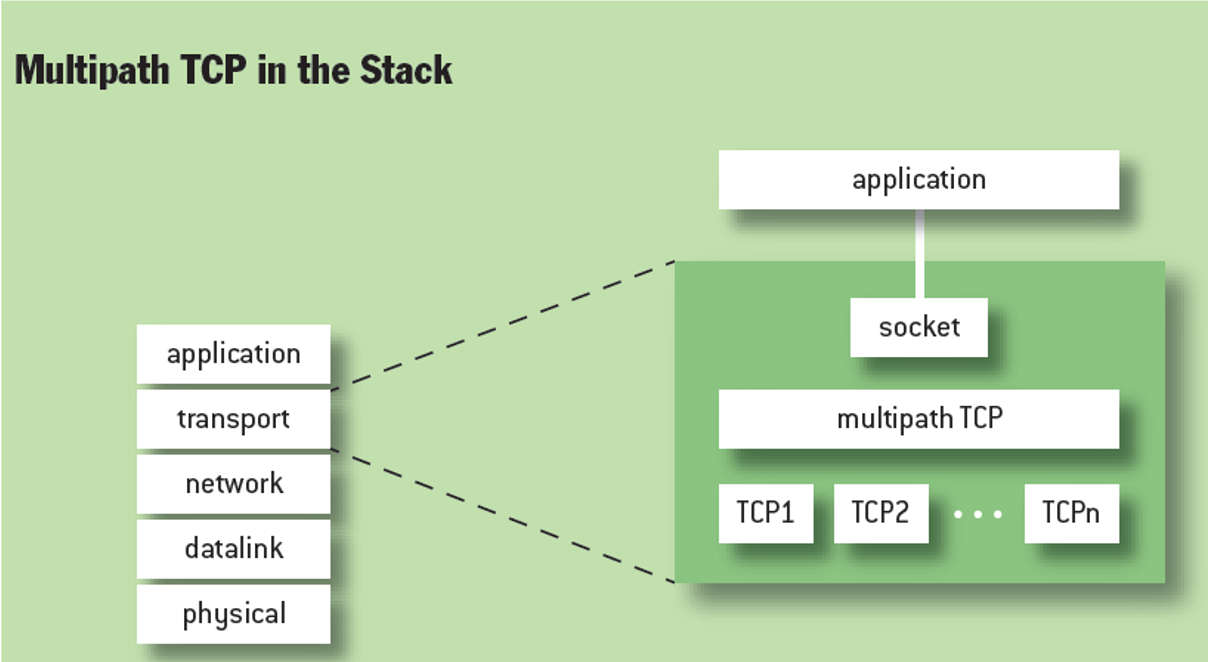
MPTCP位于传输层中,TCP和套接字之间,其不改变TCP和套接字本身内容,可以为每个MPTCP连接创建多个子流。MPTCP仍然三次握手协议,其在TCP的options字段设置MP_CAPABLE字段(通常没有用)。如果想申请建立MPTCP连接,就设置MP_CAPABLE字段,同时如果对方回应的ACK中也包含MP_CAPABLE字段,那就表面双方都可建立MPTCP连接。连接申请方在回应一个ACK,即可建立一个MPTCP连接,这个连接可称为一个MPTCP的子流。

经过多次MPTCP的握手,就可以建立多个MPTCP子流。同时,这些子流可以同属于一个MPTCP连接。为了识别同一个MPTCP连接的子流,MPTCP给每个子流分配一个独特的token。SYN的MP_JOIN字段包含了识别同属于一个MPTCP连接的token。
MPTCP拥塞控制的目标
MPTCP的多个子流实际上是为同一个应用程序服务的,以确保这个应用程序能很好地服务于用户。在数据传输过程中,MPTCP的多个子流可能拥塞,而有的地方却畅通无阻。MPTCP的拥塞控制实际上是为了决定有拥塞的和没拥塞的地方怎么分别处理,有拥塞的地方要发生退让,没有拥塞的地方要能拿到带宽,让数据尽可能从没有拥塞的链路发送。
举个例子,当人在开启蜂窝数据并连接WiFi的情况下,观看视频时,如果WiFi信号质量变差,数据就可以转而通过蜂窝数据接收。这也是MPTCP的一个直观需求,可能想法就是从这里来的。MPTCP早年已经做到Apple的手机系统里面了,可以开启一个选项来用蜂窝数据优化WiFi信号差时的数据传输。但现在还不知道有没有,因为一直没用过苹果手机。
2.MPTCP拥塞控制的关注点
- 怎么实现TCP流的公平性。(EWTCP太公平,而Coupled又太不公平。)
- 怎么发现并利用不那么拥挤的路径。
- 怎么适应负载变化。
- RTT不匹配。(子流之间的RTT不一样,对应拥塞程度不一样。)
3.EWTCP、Coupled和MPTCP是如何表现的?
传统TCP:
基本思想:AIMD——Additive Increase / Multiplicative Decrese

EWTCP(Equal Wait TCP):

子流之间是独立的,拥塞控制窗口的增减只跟这个子流上的丢包和ACK有关系。流与流之间发生的拥塞并不会相互影响,并且他们之间都是平等的,会平均分配所走链路的总带宽。
Coupled:

每条子流的拥塞控制窗口的增加和减少都都跟全局相关。对于有较多丢包的子流,其窗口会经历更多的削减。如果子流的丢包率比所有路径的最小丢包率高的话,这条路径的拥塞控制窗口将变为0。这意味着,这个算法总是会使用拥塞最少的路径。
每个流考虑其子流所走的每个路径,只使用这些路径中拥塞最少的路径,不能发现其他良好的路径。
存在问题:当之前的拥塞路径变好了,拥塞控制算法并不知道,因为已经完全抛弃了那条路径。

其中,$\omega_r=\sqrt{2a}\frac{\frac{1}{p_r}}{\sqrt{\sum_s\frac{1}{p_s}}}$,${p_r}$为r这个子流的丢包率,${p_r}$指代所有子流的丢包率(会在分母上求和)。
进而提出SEMICoupled,这个算法的拥塞控制窗口增加跟全局相关,而窗口减小只跟自己相关,这样就永远不会使得自己的窗口减小为0。当拥塞链路变好之后,可以用这个小的拥塞窗口去检测,并重新利用那条路径。
为什么SEMICoupled算法窗口不会减小为0:因为SEMICoupled的窗口减小只跟自己相关,每次都是对半减少,用减不到0。而Coupled算法的窗口减小是跟全局相关的,如果当前窗口小于要减去的那部分窗口,直接变成负数了(因为全局相关的窗口可能是比单个流的窗口要大的),这意味着没有数据在这条路径传输,可认为窗口大小变为0。
MPTCP:
MPTCP介于EWTCP和Coupled之间,其子流的窗口增加会考虑所有子流的窗口大小,而窗口减小只考虑子流自身的窗口大小。
考虑到以上几种算法在进行拥塞控制时,都认为每条子流的RTT是一样的,没有把RTT考虑在内。当不同传输链路的RTT不匹配时,会导致很低的吞吐。考虑同时使用WiFi和3G进行数据传输的场景,WiFi具有高丢包率,低RTT,而3G具有低丢包率和高RTT。
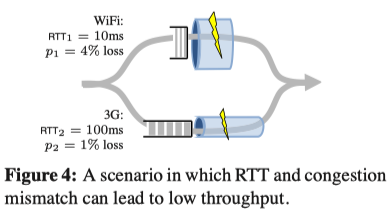
几种不同控制方案所获得的吞吐归纳如下:
Single-path TCP:WiFi上,吞吐为707pkt/s;3G上,吞吐位141pkt/s
EWTCP:每个路径各传输一半, 吞吐为(707+141)/2=424pkt/s(公平对待每个传输路径,而没有更多地使用高吞吐的WiFi)
Coupled:全部数据都通过3G,141pkt/s的吞吐(WiFi的高丢包,导致其弃用了大吞吐的WiFi)
可以看到用了EWTCP和Coupled算法所获得的吞吐甚至不如不用MPTCP,只在WiFi上所获得的吞吐大,这背离了MPTCP的初衷。
MPTCP就把RTT考虑在内,进行拥塞控制。以下算法是从上面拓展而来的MPTCP算法,实际的MPTCP拥塞控制算法是以下算法的一种推广形式。

- 最多增加$1/w_r$,所以不会比常规TCP更激进
- $a$控制激进性
- 最终的MPTCP算法是该算法的推广
最终的MPTCP拥塞控制算法:

注:拥塞控制窗口实际上就是决定一段时间内发送数据多少的窗口,这个概念跟传统是一样的。
判断EWTCP和Coupled各自获取的带宽
EWTCP:在同一个链路传输的多个子流平均分配带宽,MPTCP连接的多个子流带宽加和即为总带宽。
Coupled:将总带宽平均分给大的MPTCP流,再将单个MPTCP流的带宽分给其他子流(子流的分配并不一定平均)。
例图:

在左边EWTCP的例子中,对于flowA,第一个子流单独占用对应链路的5Mb/s,而第二个子流和flowB的第一个子流共用一个链路,所以将该链路带宽平均为6Mb/s,以供两条使用。那么,flowA总带宽为:5Mb/s+6Mb/s=11Mb/s,flowB和flowC都类似。最终,flowB占用6Mb/s+5Mb/s=11Mb/s,flowC占用5Mb/s+3Mb/s=8Mb/s。
在右边Coupled的例子中,每个Coupled的流所能拿到的带宽只和最不拥塞的链路上的丢包率有关。而这里4条链路的丢包率都一样(假设如此),而每个流的总窗口大小又取决于丢包率,所以每个流所拿到的总带宽都一样。所有的总带宽为30Mb/s,将其除以flow数目,即得到每个flow的总带宽都为10Mb/s。但每个流的子流所占用带宽取决于这样一个事实(没搞懂):

思考:
这里MPTCP的拥塞控制算法还是基于丢包,因为它发表时间是比BBR早的。而在学习过BBR之后,就知道这种思想在现在的网络设备上是不合适的。所以感觉能用BBR的拥塞控制思想去做MPTCP的拥塞控制。谷歌学术搜索关键字:mptcp+bbr,马上就看到了各种组合优化的文章,还不乏发在各种Transaction上的文章,看来这种想法还是很自然的。另一方面,感觉大部分人都是针对已有的大工作去做优化,而真正的突破性工作还是比较少的。
软件定义网络
Ethane
原论文:Ethane: Taking Control of the Enterprise-2007
1.Ethane的原则
通过具有高层名称(high-level name)的策略(Policy)进行管理
例:“广告部门的员工不能访问财务部门的数据”即为一个Policy,而广告部门的员工和财务的数据即为high-level name,这个Policy中并不包含low-level的MAC、IP等信息。
由策略来决定路径
网络应该将数据包和其源地址进行强绑定
2.Ethane的组成成分
Controller
包含整个网络的Policy和拓扑,用来决定网络中哪些主机之间可以进行通信。若主机之前可以通信,Controller会计算它们之间的路径。
Ethane switch
包含一个简单的流表(Flow table)和一个与Controller之间的安全通道,其构造简单,只根据Controller所做的指示去转发数据包。
3.Ethane网络中的Name binding
Controller会实现machine-address-user三者之间的绑定。当一个机器申请接入网络时,Controller会给这个机器分配一个IP地址,这就实现了machine-address的绑定。同时,还需要用户通过一个网络界面进行用户名和密码的验证(有点类似学校的校园网登录),这样就实现了machine-address-user三者之前的映射。
当组件在网络中连接、离开和移动时,Controller会同时保持名称空间(namespace)的一致性。
好处:
- Controller可以跟踪任何实体的位置;
- Controller可以将所有绑定和流条目(flow-entries)记录在日志中,用于网络事件重构。
思考:Controller其实就是针对实体用户进行管理,实现精确的行为控制,拒绝所有未经允许的行为。感觉这个思想有点类似安全中的访问控制了。另一方面,如果把这套东西用到企业中,感觉就不会受到以往的各种传统网络攻击了。首先网络架构变了,以往各种针对传统交换机和路由器的攻击必然行不通。其次,Controller实现了machine-address-user三者之间的强绑定,即便有一个攻击者能连接一个内网机器,实际上他也会由于没有用户认证信息,导致Controller拒绝其接入网络。
4.Ethane网络中的两台主机怎么通信?
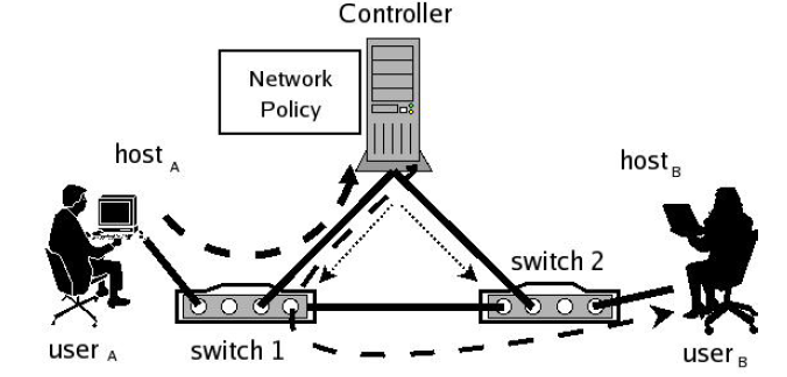
主要分为三步:认证(Authentication),流设置(Flow Setup)和转发(Forwarding)。
- 认证
- UserA通过HostA连接网络,交换机1最初将HostA的所有数据包转发给控制器;
- HostA向Controller发送DHCP请求。Controller将HostA与A的IP、A的AP与A的MAC、A的MAC绑定到交换机1的物理端口上;
- UserA打开一个web浏览器,它的流量被定向到Controller,并通过一个web表单进行身份验证。
- 流设置
- 交换机1在确定报文不匹配其流表中的任何活动表项后,将报文转发给Controller;
- Controller决定是否允许或拒绝流,或者要求它遍历一组路径点;
- Controller计算流的路径,并在该路径上所有交换机的流表中添加一个新条目。
- 转发
- 如果路径允许,Controller将数据包发送回交换机1,交换机1根据新的流条目转发数据包;
- 该流的后续报文直接由交换机转发,不再发送给Controller;
- 流入口(flow-entry)保持在交换机中,直到超时。(如果流表规则超过一段时间没有被使用,交换机就认为这个规则暂时没用了,之后会将其删去。)
5.Controller备份(Controller Replicating)
因为Controller是整个网络的核心,关键事物都需要它做决策,一旦它瘫痪了,整个网络将无法工作,所以它的备份即为关键。这里有三种方式:冷备份(Cold standy),热备份(Warm standy)和完全备份(Fully-replication)。
冷备份:备份控制器处于闲置状态——等待在需要时进行接管。
- 如果失败,网络将收敛到MST(最小生成树)的一个新的根上。
- 备份只需要包含注册状态和网络策略。
- 它的主要优点是简单;缺点是主机、交换机和用户需要在主服务器失败时重新进行身份验证和重新绑定,网络服务将会中断。
- 路径需要重新计算。
热备份:为每个Controller创建一个单独的MST。
- 控制器监视彼此的活动,一旦检测到主控制器的故障,则次要控制器根据静态顺序接管;
- 需要跨Controller复制绑定(Controller之间共享已认证用户的信息);
- 一些新用户和主机需要重新认证(这些用户在Controller接管过程中联入网络,他们的信息由于主控制器的故障,还没有将认证信息保存到对应的数据库中)。
完全备份:两个或多个活动的Controller,它们之间是等价的。(将网络的的管理职能分配给多个Controller,每个Controller只管一部分)
交换机只需要向一个Controller验证自己,然后就可以将其流请求分散到Controller上(例如,哈希或循环);
用Gossip(流言传播协议)来提供对事件排序的微弱一致性(weakly-consistent)。
Gossip实际上就是定期进行信息交换的协议。在这里,Controller通过Gossip获取其他controller的认证信息。
通过Gossip,每个controller都可以获得整个网络的全局视图,一旦有一个controller发生故障,其他controller会将故障controller的控制信息接管过来。
6.Policy Language
Ethane网络策略(Policy)声明为一组规则,每个规则由一个条件(Condition)和相应的动作(Action)组成。
例子:[(usrc="bob")^(protocol="http")^(hdst="websrv")]:allow;
Condition:如果用户发起的流是“bob”,流协议是“http”,流目的地是主机“websrv”。
Action:操作包括允许(allow)、拒绝(deny)、航路点(waypoints)和仅出站(outbound-only)。
waypoints:允许,但是该路径要经过某一个位置或者设施。例如,让这个路径经过一个防火墙。
outbound-only:允许,但是数据只能向外走,不能向网络内部发。
规则之间是独立且等价的,并不包含内在的顺序。
OpenFlow
原论文:OpenFlow: Enabling Innovation in Campus Networks-2008
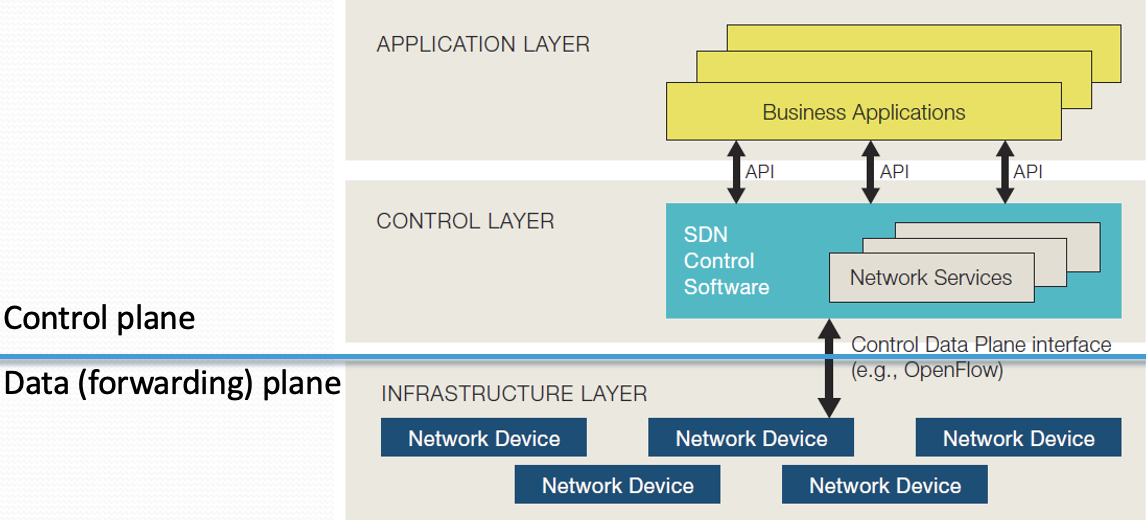
1.SDN是怎么工作的?
在SDN(Software Defined Networking)中,网络控制与转发分离,网络是直接可编程的。网络控制相关内容被抽象为控制平面(Control plane),网络转发相关内容被抽象为数据/转发(Data/Forwarding)平面。
- 网络操作员和管理员可以通过编程去配置这种简化的网络抽象。
可以自己编写相关程序,而不是等待特性嵌入到供应商的专有和封闭的软件中。 - SDN架构支持一组API,使实现通用网络服务成为可能,
比如,路由,组播,安全,访问控制,带宽管理,流量工程,服务质量等功能,并且可以定制内容,以满足业务目标。
2.SDN的三层
SDN将网络分为三层:应用层、控制层和基础设施层(图见问题1)。应用层包含用户正常使用的各种应用;控制层包含SDN控制软件,用来提供各种网络服务;基础设施层包含各种网络设备用来执行数据的转发。OpenFlow用来连接控制层和基础设施层,其提供一个控制数据平面的接口。但如果非要说其位于哪一层,那应该是控制层,因为其主要执行网络的管理控制功能。
3.OpenFlow交换机相关内容
OpenFlow提供了一个开放协议来对不同交换机和路由器中的流表进行编程。OpenFlow路由器至少由三部分组成:
- 一个流表,其带有与每个流表项(flow entry)相关联的动作(Action),用来告诉交换机如何处理流;
- 一个连接交换机和远程控制器(controller)的安全通道,其允许命令和报文在控制器和交换机之间发送;
- OpenFlow协议,它为控制器与交换机通信提供了一种开放而标准的方式。
什么是流?
- 一个流可以是TCP连接,也可以是来自特定MAC或IP地址的所有数据包,也可以是带有相同VLAN tag的所有数据包,也可以是来自同一个交换机端口的所有数据包;
- 一组具有相同特征的数据包序列。
什么是Action?
每个流入口都有一个与之相关联的简单动作(Action),用来指示怎么处理相应数据包,动作可以分为以下几个种类:
- Foward:将该流的数据包发送到给定的端口(或多个端口)。
- Packet-In:向控制器报告该流的数据包。
- Drop:丢弃该流的数据包。
- Modify:修改部分字段。
OpenFlow交换机流表的内容
流表中的一个条目有三个字段:
- 定义流的包头(Header);
- 操作(Action)定义了应该如何处理数据包;
- 统计信息(Statistics),其保留每个流中包和字节的数量,以及自从上次包匹配以来的时间。
4.怎么使用SDN?
这里以OpenFlow的使用,举了几个例子。
1.网络管理与访问控制
- Ethane:基本思想是允许网络管理员在中央控制器中定义一个全网范围的策略,该策略通过对每个新流做出准入控制决定,来直接强制执行;
- 控制器通过管理名称和地址之间的所有绑定,将信息包与其发送方关联起来——它本质上接管DNS、DHCP,并在所有用户加入时,对其进行身份验证,跟踪他们连接到哪个交换机端口(或接入点)。
2.VLAN
- 最简单的方法是静态地声明一组流,指定给定VLAN ID上的流量可访问的端口;
- 更动态的方法是使用控制器来管理用户的身份验证,并通过用户的位置信息来在运行时标记流量。
3.移动无线VoIP客户端
- 对于有WiFi的手机,支持通话切换机制(call-handoff mechanism);
- 实现一个控制器来跟踪客户端的位置,当用户在网络中移动时,通过重新编程流表来重新路由连接,允许从一个接入点无缝切换到另一个接入点。
4.不处理流,只处理报文
- 法1:默认情况下,强制流的所有数据包通过一个控制器。更灵活,但它以性能为代价。
- 法2:将它们路由到进行包处理的可编程交换机。
NOX
原论文:NOX: Towards an Operating System for Networks-2008
NOX是一个早期的网络控制器原型,并非操作系统,现在一个主流的操作系统叫做ONOS(Open Network Operating System)。一个小问题:NOX和OpenFlow的区别?个人感觉像冯诺伊曼体系计算机和图灵机的区别,前者为具体实现,而图灵机为理论指导。
现状:
- 网络通过单个组件的低级配置进行管理。
- 通过ACL阻断用户:需要知道用户的当前IP地址
- 将端口80流量强制转到HTTP代理需要大量了解当前网络拓扑
- 企业网络就像一台没有操作系统的计算机,
- 网络依赖的组件配置类似于依赖硬件的机器语言编程。
需求:
- 需要网络操作系统提供观察和控制网络的能力。
- 不管理网络本身,但提供编程接口。(感觉类似面向接口编程)
- 在网络操作系统上实现的应用程序去执行实际的管理任务。
解决方案:NOX,其与之前的区别:
- 采用集中式编程模型去编写程序;编写程序时,就好像整个网络都存在于一台机器上一样。
- 程序是根据高级抽象(例如,用户名和主机名)来编写的,而不是低级配置参数(例如,IP和MAC地址)。
NOX的主要组成部分:
- 一组交换机,需要支持OpenFlow抽象。
- 一个或多个与网络连接的服务器,其上运行NOX软件,并且有一个网络视图(network view)会存在于一台服务器上运行的数据库中。
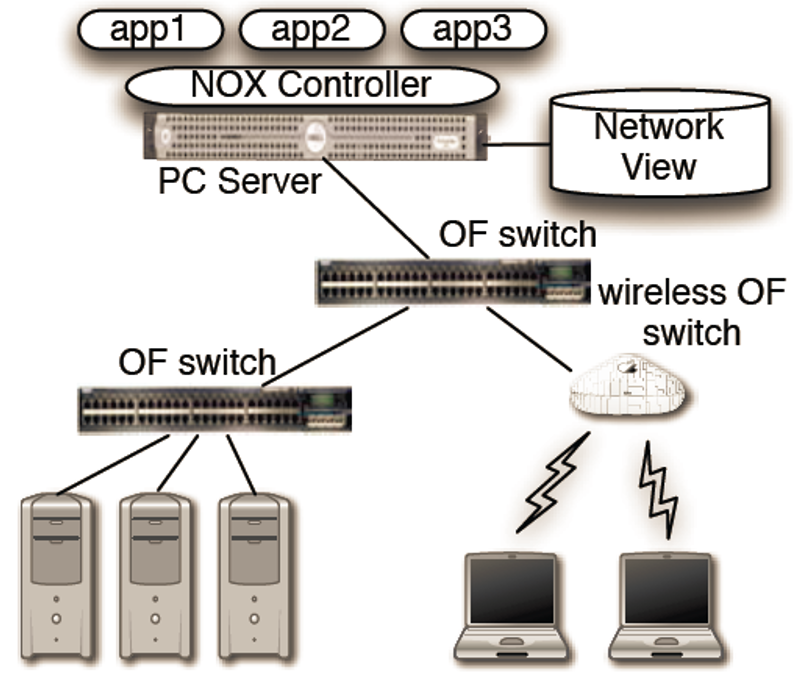
NOX的Network View:
- 是一个switch-level的拓扑(能知道交换机之间的端口连接情况);包含用户、主机、中间框和其他网络元素的位置;以及所提供的服务(如HTTP或NFS)。
- 包含所有名字和地址的绑定。
- 不包含网络流量的当前状态(太过动态,难以维持)。
1.为什么基于流的控制粒度(granularity)比包级和前缀级的控制粒度更好?
- 集中的逐包控制(per-packet control):在任何规模较大的网络上都不可行。(没有可伸缩性)
- 基于前缀的路由表(prefix-based routing):不允许足够的控制,因为两个主机之间的所有数据包必须遵循相同的路径。(没有灵活性)
- 位于以上两者之间——基于流的粒度(flow-based granularity)
一旦某些数据包受到控制,后续具有相同报头的数据包也将受到相同的处理。(灵活性与可扩展性的权衡)
2.在NOX中,哪个是全局网络视图,哪个不是?
- 交换机级拓扑(Switch-level topology)
- 名字绑定(Name binding)
- 包状态(Packet states)
- 流状态(Flow states)
对于交换机级拓扑和名字绑定,其存在于网络视图中,保持全局一致。包状态和流状态不是网络视图的一部分,只保存在本地的交换机存储中。
FlowVisor
原论文:Can the Production Network Be the Testbed?-2010
出发点:现在都需要事先将各种网络协议做到网络设备中,生产出来的网络设备由于不支持拓展功能,导致网络协议的许多新想法最终都无法在生产网络中得到测试。同时,许多已经做到网络设备中的协议存在很多漏洞,这是由于网络的实验床很难去模拟真实的网络。
基本想法:对生产网络虚拟化,生成多个网络切片,用部分切片来做实验,而其他切片用于生产网络,两者之间互不影响。
相关想法概述:
将生产网络划分为逻辑切片
- 每个片/服务控制自己的数据包转发
- 用户选择由哪个片控制他们的流量:选择进入
- 现有的生产服务在它们自己的片中运行,例如:生成树、OSPF/BGP等协议
强制片之间的强隔离
一个切片中的操作不会影响另一个切片
允许(逻辑)测试平台镜像生产网络
可以利用真实的硬件、性能、拓扑结构、规模、用户
1.FlowVisor如何在交换机和切片控制器(slice controller)之间代理?
在控制平面和数据平面之间,添加一个切片层(Slicing Layer)。 添加切片层之后,控制平面就可以放多个控制器,每个控制器控制一部分的流表,去处理一部分的Excepts。每个Except发生之后,切片层根据Slice Policies决定其被交给哪个控制器处理。
Rules:控制平面下发的数据转发规则。
Excepts:数据平面对数据包应用Rules,所做出的反馈。
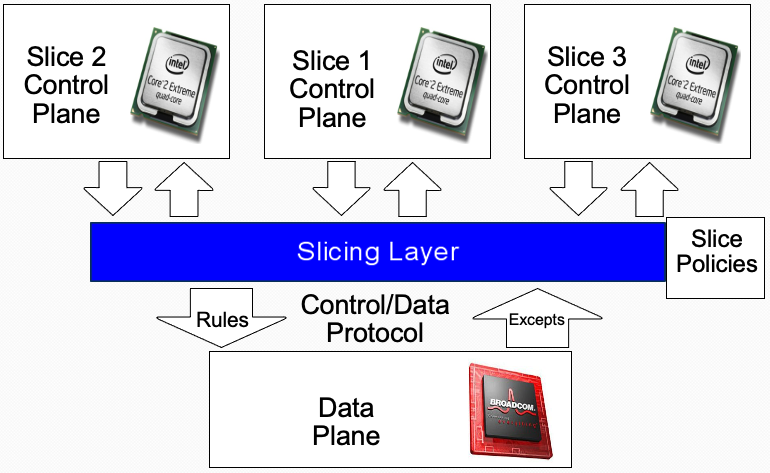
网络片是一组切片交换机/路由器的集合
数据平面没有被修改;
转发数据包没有性能损失;
用现有的ASIC切片;切片层是透明的
每个切片都认为自己拥有数据路径;
强制片之间的隔离,也就是说,重写,删除规则以遵守slice策略;
将异常(exception)转发到正确的slice;
2.如何翻译信息?
使用FlowVisor作为中介,去连接控制平面和数据平面,FlowVisor其实也就是上面的切片层。FlowVisor用OpenFlow和交换机以及控制器进行连接。对于交换机,FlowVisor表现为控制器;对于控制器,FlowVisor表现为交换机。
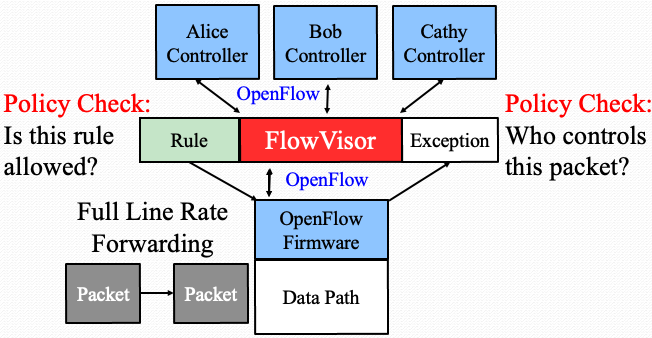
交换机到控制器的信息
当收到一个数据包时,交换机会先查询其自身流表项,看是否能处理。如果不能,就会产生一个Exception事件,将其交给FlowVisor。FlowVisor通过Policy Check来检测这个Exception由哪个控制器负责,将其交给对应的控制。
控制器到交换机的信息
收到对应Exception的控制器,根据其自身的应用程序,产生一个规则。控制器将规则交给FlowVisor,FlowVisor通过Policy Check来检测这个规则是否在这个控制器的权限之内。必要时,FlowVisor会做一些改写,以让这个规则符合对应控制器的权限。在检查完,规则被下发给交换机。交换机依据这个规则去处理后续的数据包。
3.如何实现隔离(isolation)?
通过Slice Policy来实现隔离。这里对几个方面来进行分配。
- 带宽。根据实际带宽,来给不同Slice分配不同带宽。
- 流表项。根据实际流表项大小,对每个Slice做出所能下发流表项的限制。
- 拓扑结构。不同切片网络所对应的虚拟拓扑是不一样的,需要拓扑进行限制。
- 设备CPU。在交换机的CPU上运行的OpenFlow会与不同的Slice进行交互,不能让某个Slice将计算资源消耗完,否则会导致其他的Slice无法与交换机进行交互。在跟每个Slice交互时,对交换机所能使用的CPU资源进行限制。
- 流空间(FlowSpace)。确保不同Slice所管理的数据包不同,不会发生冲突。这个从下面这张图进行理解,假设只看MAC、IP和TCP端口。每个包都会有确定的三个值,这样就可以通过限定MAC、IP和TCP端口的范围,来划分不同Slice的管辖空间。
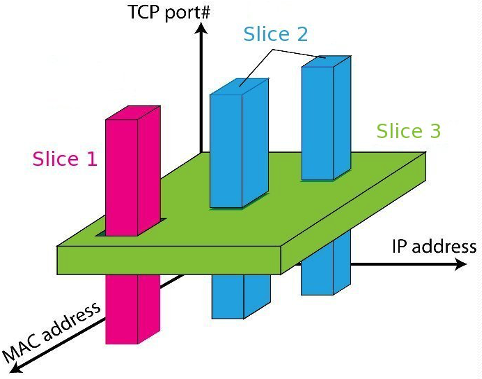
思考:
感觉这个FlowVisor的想法很类似于面向对象,因为交换机和控制器之间需要进行交互,直接添加一个额外的组件可能没法直接使用。那FlowVisor的思想就是对不同的对象表现出不同的行为,而跟它交互的组件只需要FlowVisor能表现出预期的行为即可,并不关心其到底是什么。
Pyretic
注:Pyretic是编写控制器的编程语言,而P4是编写可编程交换机网络协议的编程语言。
1.抽象的包模型
Pyretic依赖于抽象的包模型。在Pyretic中,一个抽象数据包含有所有OpenFlow可识别的字段:Srcmac, dstmac, ethertype, srcip, dstip(原始数据包自带的),以及switch,inport,outport等其他信息(数据包上报时,交换机所添加的)。而且每个字段的数据结构是一个栈,涉及到Push和Pop,后面的虚拟网络和物理网络映射就是基于这个数据结构的。
2.基础策略及代码执行
Pyretic包含几种基础的Policy,分别为Filter Policy、Query Policy和Dynamic Policy。
Filter Policy:不改变数据包,要么返回只包含数据包的集合,要么返回空的集合。
Query Policy:用来追踪网络的事件,其作为一个网络监视器。
Dynamic Policy:动态地调整网络行为的Policy。Query Policy通常用于驱动对其他Dynamic Policy策略的更改。根据程序员的规范,Dynamic Policy具有随时间变化的行为(通过self.policy定义)。
例子:例程round_robin从一个新客户端(源IP地址)获取第一个数据包,并更新策略的行为(通过给self.policy指定一个新值),之后,从这个源发送的所有未来数据包都按顺序分配给下一个服务器(通过重写目的IP地址)。
代码及理解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32'''
通过继承DynamicPolicy并提供一个初始化方法来将round_robin注册为回调例程,进而创建一个新的“轮循负载均衡器”动态策略类rrlb:
'''
class rrlb(DynamicPolicy):
def __init__(self, s, servers):
self.switch = s
self.servers = servers
...
Q = packets(limit=1,group_by=['srcip'])
Q.register_callback(self.round_robin)
self.policy = match(dstport=80) >> Q
'''
对原有self.policy包了一层判断,来自所有其他客户机的数据包将像以前一样处理;而满足条件的包将会重写服务器IP,更新策略。在更新策略之后,round_robin还会将“当前向上”的服务器移动到列表中的下一个服务器。(不同IP对应不同服务器,以负载均衡)
'''
def round_robin(self,pkt):
self.policy = if_(match(srcip=pkt['srcip']),
modify(dstip=self.server),
self.policy)
self.client += 1
self.server = self.servers[self.client % m]
'''
以标准方式创建一个rrlb的新实例(比如运行在交换机3上,并向2.2.2.8、2.2.2.9和2.2.2.10的服务器副本发送请求)
下面就会以rrlb所定义的方式对服务器进行轮询负载均衡。
'''
servers = [IP('2.2.2.8'),IP('2.2.2.9'),IP('2.2.2.10')]
rrlb_on_switch3 = rrlb(3,servers)
'''
在上面,关键是理解rrlb中的Q.register_callback通过回调round_robin来对self.policy进行动态地改变,这即为Dynamic Policy。
'''
Learning Switch的例子
Learning Switch:看到一个新的源MAC地址,控制器就会在交换机流表上下发一个新的目的MAC地址和对应交换机端口的流表项。
代码:
1 | from pyretic.lib.corelib import * |
3.什么是网络对象?
网络对象(Network Object):允许程序员抽象出物理拓扑的细节,并根据网络的抽象视图编写策略。
基本网络对象(Base Network Object)表示物理网络。
派生网络对象(Derived Network Object)实现抽象拓扑。可认为是虚拟网络。
派生网络对象的映射包括以下函数:
将对底层拓扑的更改映射到派生拓扑的更改的函数;
原文:A function to map changes to the underlying topology up to changes on the derived topology.
将根据派生拓扑编写的策略映射到仅根据底层拓扑表示的语义等价策略的函数。
原文:A function to map policies written against the derived topology down to a semantically equivalent policy expressed only in terms of the underlying topology.
4.转换策略
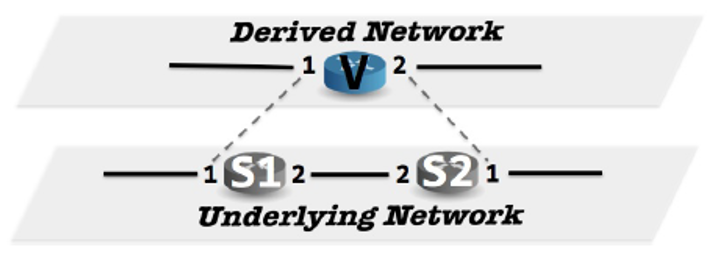
为了根据用户代码,去实现物理网络和抽象网络的映射(用户针对抽象网络进行编程,他并不知道实际物理拓扑到底是什么样的),需要以下几种转换策略:
- Ingress_policy(进入策略):将底层网络中的数据包“提升”到派生网络。
- Egress_policy(外出策略):将包从派生网络“降低”到底层网络。
- Fabric_policy(构造策略):利用底层拓扑中的交换机和链路,实现派生网络中相邻端口之间的转发。
在上图的例子中,理解如下:
Ingress_policy:将派生的switch V和inport推送到对应的虚拟报头栈上。
理解:当包进来的时候,根据其物理拓扑的位置,为其分配虚拟拓扑的位置。如果包在S1的port1,那就将其对应到V的port1;如果包在S2的port1,那就将其对应到V的port2。
Code:
1
2
3ingress_policy =
( match(switch=S1, inport=1) [push(vswitch=V, vinport=1)]
| match(switch=S2, inport=1) [push(vswitch=V, vinport=2)])Egress_policy:如果交换机标记为派生交换机V,则从相应的虚拟报头堆栈弹出派生交换机、输入端口和输出端口,否则未经修改就让包通过。
理解:如果在虚拟拓扑中,数据包位于交换机V,物理位置为S1和出口1或者为S2和出口1,那么就将相应的虚拟信息弹出。这个包就没有虚拟拓扑的位置了,变成一个普通的,只有物理拓扑的包。
Code:
1
2egress_policy =
match(vswitch=V) [if_(match(switch=S1, voutport=1) | match(switch=S2, voutport=2), pop(vswitch, vinport, voutport), passthrough)]Fabric_policy:沿着S1和S2之间的唯一路径转发带有派生交换机V的数据包:
理解:如果在虚拟拓扑中,数据包位于交换机V,出端口为port1,且物理拓扑在S1,那就可以直接从S1的port1转发出去(对应下面代码的第1个匹配)。;而如果物理拓扑在S2,要想从虚拟交换机V的port1出,物理拓扑只能先从S2的port2转发,S1收到之后,再从port1转发(对应下面代码的第3、2个匹配)。
Code:
1
2
3
4
5fabric_policy = match(vswitch=V)[
( match(switch=S1, voutport=1)[fwd(1)]
| match(switch=S1, voutport=2)[fwd(2)]
| match(switch=S2, voutport=1)[fwd(2)]
| match(switch=S2, voutport=2)[fwd(1)])]
Odin
原论文:Programmatic Orchestration of WiFi Networks-2014
1.Odin的架构
类似SDN的思想,有一个控制器和受控制的个体。不过这里的控制器在OpenFlow之后,加了一点东西称为Odin控制器。同时,对于受控的无线AP来说,其上的Odin代理会跟Odin控制器进行通信。
Odin控制器:
- 向应用程序公开接口,
- 维护一个网络视图,包括客户端、AP、OpenFlow交换机。
Odin代理:
- 在无线AP上运行,其处理传入的帧
- 时序要求严格的WiFi MAC功能由AP硬件实现(例如,ACK)
- 时序要求不严格的功能由控制器和代理实现(例如关联、认证等)
应用程序:
- 访问测量(从代理和OpenFlow统计收集的度量)
- 做出控制决策
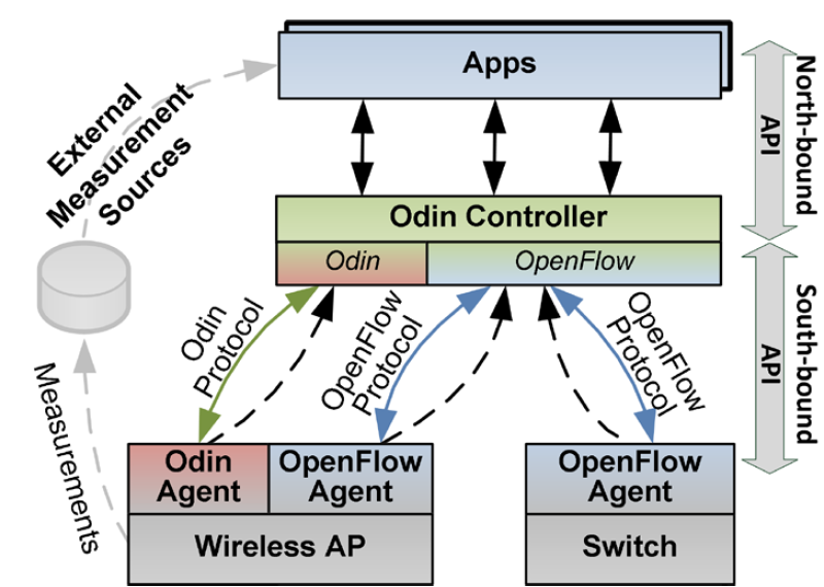
2.每个客户端的LVAP(per-client LVAP)的实现
出发点:在常规的IEEE 802.11网络中,客户端在发送数据帧之前需要与物理AP关联。关联过程从发现阶段开始,在这个阶段,客户端要么通过生成探测请求主动扫描AP,要么通过后者生成的信标帧被动地学习AP。在主动扫描期间,使用探针响应消息进行响应的AP成为客户端关联的候选AP。然后,客户端通过本地做出的选择来决定与哪个AP关联。此时,这定义了客户端的MAC地址和AP的BSSID的关联关系。BSSID是AP无线接口的MAC地址,与SSID不同,SSID是一个网络名称。这样设计的WiFi协议不方便,其没有对客户机关联进行集中控制的机制,因为客户机完全依靠自己做出关联决策。此外,如果不引入额外的信号技术,基础设施就不能指示客户机重新关联。
LVAP方法克服了这些困难,没有在客户端和基础结构之间引入额外的信号机制,因此符合不引入客户端修改的目标。使用LVAP,每个客户端接收一个唯一的BSSID来连接,本质上使LVAP成为客户端特定的AP(意思就是一个LVAP只给一个客户服务,是一对一的关系)。
LVAP(Light Virtual Access Points)是一个per-client AP,它简化了客户端关联、身份验证、切换和网络有线和无线部分的统一切片的处理。它使WiFi网络的端口-源(port-per-source)视图类似于有线网络。LVAP托管在代理上,它们对代理的分配由控制器控制。
在Odin中,每个客户端都有一个per-client LVAP,其技术描述:
- 每个客户端由控制器分配一个具有唯一BSSID的LVAP
- 一个物理AP承载多个LVAP
- 物理AP通过LVAP的BSSID来指引LVAP的迁移
- 客户端与它的LVAP相关联,而不是物理AP
对于每个关联的客户端(通过客户端WiFi MAC地址识别),都有一个对应的LVAP。LVAP包含以下信息:一个唯一的虚拟BSSID、一个或多个SSID、客户端IP地址和一组OpenFlow规则。通过加密,会话密钥将成为LVAP状态的一部分。当LVAP从一个物理AP迁移到另一个物理AP时,所有对应的状态(BSSID、SSID、客户端IP地址、OpenFlow规则)也会随之迁移。由于LVAP的BSSID总是一致的,客户端不执行重新关联。通过将一组OpenFlow规则绑定到LVAP,并允许应用程序对AP的无线和有线端进行编程,使得LVAP的框架与OpenFlow集成在一起。

下图显示了使用LVAP处理客户端关联的决策流。
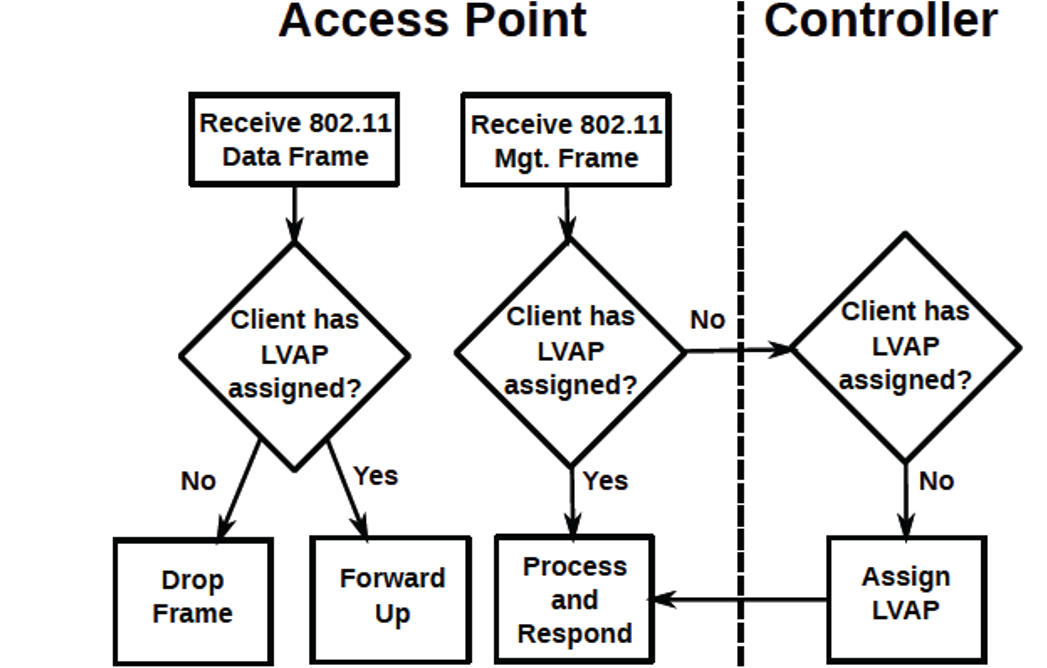
3.如何用Odin管理客户端的移动?
在物理AP间迁移LVAP,而不是客户机重新关联
当客户端探测扫描时,一个新的LVAP在物理AP上的Odin代理中生成。然后,这个LVAP根据控制器的指示用一个探测响应响应客户端,然后,客户端完成与它的LVAP的关联握手。因此,一个物理AP为每个连接的客户端托管一个唯一的LVAP。每个LVAP定期单播信标帧到它对应的客户端。这可以确保客户端永远不会处理来自另一个客户端的LVAP的信标帧。
只要客户机接收到它生成的数据帧的ACK,并从它关联的AP(在本例中是一个LVAP)接收到信标,客户机就保持关联。如果与客户端的LVAP对应的状态足够快地迁移到另一个Odin代理并实例化,客户端就不会试图重新扫描。因此,通过在物理AP之间迁移客户机的LVAP,基础设施现在可以控制客户机到网络的连接点,而不需要在客户机上触发重新关联。但如果由于LVAP迁移到远端AP,客户端信号强度显著降低,则客户端将执行常规重新扫描。
理解:
Odin把跟客户端交互的AP抽象为LVAP,客户端认为LVAP就是它想要通信的对象。同时,当用户移动时,其跟物理AP上的LVAP之间的通信仍会继续。由于客户端跟WiFi通信是广播的,多个物理AP都会收到同一个客户端的信息。这时,多个物理AP将信息上报给控制器,控制器会根据物理AP的RSSI,将LVAP迁移到RSSI最好的物理AP上。通过,物理AP上的LVAP迁移,实现了用户无感的AP切换。
学习感想
首先感谢计算机学院田野老师的细致授课,田老师总是能把很抽象的例子用直观的图和语言将其描述出来,使得我们理解起来比较轻松,这一点比大部分老师都好多了,但就是语速有点快。学完这门课,最重要的收获是对近期的计算机网络研究内容有所了解,选这门课的目的其实也就是为了这。而且,能够知道本科所学的一些经典TCP/IP知识可能都过时了,印象最深的就是HTTP/3将抛弃TCP,完全使用UDP以及真正基于拥塞的拥塞控制算法——BBR。
下面简要谈谈自己对计算机网络的相关想法和理解。本科所学的内容主要是经典的TCP/IP协议族,是计算机网络发展早期的工作,主要用于满足基础的局域网,互联网等网络的连通与数据传输工作,其也是现在大量应用的网络设备的基础理论。但随着计算机顶层应用的不断发展,其实也对网络的方方面面提出了更高的要求。为了满足这些要求,相关学者也在围绕TCP/IP去做一系列改进和提升,但由于TCP/IP设备应用过于广泛,所做的修改其实并不能很大,以实现后向兼容的目的,可以认为是“带着镣铐跳舞”。终于,有一群人受不了了,搞了一个叫做SDN的东西,开端论文是Martìn Casado等人发表的Ethane: Taking Control of the Enterprise和Nick McKeown等人发表的OpenFlow: Enabling Innovation in Campus Networks。SDN全称为Software Defined Network,中文名叫软件定义网络。
SDN对网络功能进行抽象,通过控制平面和数据转发平面之间的开放接口分离了它们的角色。SDN将控制平面抬起并脱离交换机,将其置于外部软件中。这种对数据转发平面的编程控制允许网络所有者在复制现有协议行为的同时,向他们的网络添加新功能。
P. Bosshart et al. “Forwarding Metamorphosis: Fast Programmable Match-action Processing in Hardware for SDN”. In: ACM SIGCOMM ’13.
简单来说,SDN使得网络控制和数据转发相分离,而近期提出的可编程交换机使得数据转发平面可以编程,开发人员可以按照自己的想法去设计数据平面的各种算法,而不是像以前一样,只能调用嵌入到网络设备中的基础算法。就像现在广泛使用的计算机一样,人人都可以写代码去创造新的理论和方法。这使得网络研究者和管理员有什么想法都可以直接写代码进行快速验证,而不必等到设备商兼容或者是在不真实的测试平台上验证。虽说这种想法很棒,但它还是需要专门的设备,比较经典的是Barefoot Networks的可编程交换机,而且已经商业化并量产了。
虽说SDN掀起了网络领域的革命,但还是没有得到大量应用,常见的就是Google,阿里等拥有大型网络的公司和大学实验室会搞这些东西,SIGCOMM等顶会上都不乏他们的身影。而对于一些小型公司,以前的经典网络设备其实就能满足需求,并没有必要去使用这个新技术,而且如果使用了SDN相关技术,相应会对网络管理原有更高的要求,相应的薪资也是一个不小的开销。所以,SDN的推广应用还任重而道远。但即便如此,SDN及其下面的可编程交换机还是近期网络领域的一个研究热门,因为可编程带来的灵活性实在是太大了,同时,传统网络研究的各种方向都可以用SDN去重构(水论文)。
其他想法
曾经很想搞计算机网络相关的研究,但是学了之后,又觉得没那么感兴趣了。一方面,可能是自己觉得一些工作的细节太多了,自己难以去搞这样的研究;另一方面,是觉得现在他们的应用范围还是比较窄,搞了之后,知识的应用范围也还是受限的。颇有一种叶公好龙的感觉。
但仔细想想,自己现在看的都是顶会论文,那这些论文必然是做了大量的工作才能在顶会发表,而自己作为一个刚入门的研究生,想要一下做出来这样的工作,也是极为困难的。而对于研究的话,其本就是探索的工作,能直接应用于产业界的工作可以说是少之又少,基本上都是在不断累积的。只是近几年的深度学习的大规模推广应用,造成了一种研究都能得到快速成果转化的一种假象,这可能也使得我对研究产生了误解,以为研究就是要搞出来什么能直接应用的。而一些毕业的博士也未必会从事跟他们研究相关的工作,这些企业可能看中的是他们在读博期间所受到的科研训练以及各种科学素养,因为读博期间的经历和训练足够使得他们快速学习并上手其他领域。
最后是一点小想法。小时候很不理解叶公明明那么喜欢龙,但为什么见到真龙,反而又害怕的不行呢,这种故事不是太不符合常理了。但到现在,也多少是对这个成语有了一点理解。当你没有见到事物完整面貌的时候,你总是对会它们有一种滤镜,你觉得它很完美,而忽视了非常细小的细节。但是当事物完全展现在你之后,你发现它们并不是你所想的那样,你可能就会失望,甚至说讨厌。龙可以说是中国的最具代表性的一种虚构生物,大家都称赞、仰慕它,而在这样的环境下,叶公可能就因此而喜欢上了龙。而当叶公真正见到龙之后,可能又被龙的巨大体型和“狰狞面孔”而吓到。回想自己小时候看到一幅描述叶公好龙这个成语的图片,叶公正坐在窗户边与友人攀谈,突然,窗户外出现一个“张牙舞爪”的躯体。想想一下,狭窄的窗口视野范围,而一个从来没见过的生物又贴的非常近,脸部的各种细节都清晰可见,这种情况是多么的吓人(有点进击的巨人那味儿了,巨人贴在窗口那一幕可以说是非常、非常的吓人,如果不注意,还是会被吓一跳的。)。在这样的情况下,叶公难免会大惊失色,仓皇逃窜。龙本身也不理解叶公的行为,就马上走了。但如果两者能在多一些时间了解的话,可能也就不会有“叶公不好龙”了,反而会加深叶公对龙的喜爱。我想,有些时候,我们需要对事物的更全面理解,才能避免叶公好龙。
写到现在,很自然地,又有了一点相关的想法。或许,科研就是这么一条龙,说谁谁是搞科研的,我们都会竖起大拇指,对他/她绝口称赞。在这样的环境下,就会有人有科研理想,想要做出一番成就。但实际上,科研跟其他领域也都一样,其本身也存在各种问题,它的种种细节肯定不会是大家所想的那么完美(对于这一点,知乎都能搜到很多)。对于初入门路的“叶公”来说,可能也就会因此而失去兴趣。作为一个刚刚满一年的研究生,自己也确实是了解了科研本身的一些“脏”细节,自己并不喜欢那样的研究思路和做法,但人家就是做得风生水起,这也算是一种能力吧。就自己的水平来说,作为一个新手,可能也没法很好地评价他们,这一点暂且不谈。另一方面,我们需要对科研祛魅,让大家都了解到事物全貌,让每个人都能自由地尝试,而非只能一条路走到黑。这一点,美国做的就很好,本科毕业,想搞学术的,基本都是直接读博士。如果发现自己不适合或者不想读了,可以退出,同时还会给一个硕士学位,找工作照样没问题。而中国的博士退出了,学位上将一无所有。国家其实也意识到了这一点,在一些学校和专业其实已经限制招收学硕了,只把研究生分为专硕和博士,想搞学术?可以,直接读博士。但我不知道,是不是也有完善的退出机制,让学生都能有自己的选择,如果退出了,还没有硕士学位,我想这还不如现在的机制。同时,还需要社会大众对于读博的正确认知,让大家都能够接受那些因为种种原因(内在和外在都有很多,对于非天才来说,读博是一个巨大的挑战)而退出的人。他们虽然在读博上失败了,但作为工作者,他们又是刚刚起步的挑战者,我们没有理由去用研究的失败来预测他们未来在其他赛道的成败。
随便写了点关于科研的想法,但其实把叶公好龙这种情况套到其他场景也都是适用的。就比如,你可能因为某些原因喜欢一个人,但当真正接触之后,你又可能会因为他/她的一些行为不符合你的期待,反而又变得不喜欢了。我想,在这一生中,人就是在不断地认知、失望与接收,但即便这样,我们也不会因此而停下脚步。
世界上只有一种英雄主义,就是看清生活的真相之后依然热爱生活。——罗曼罗兰
我们每个人都是英雄。